When a bottleneck appears in the supply chain, you just… react, right? This might feel like you are doing well. Unfortunately, there’s actually a way you could be doing even better. You need to be proactive. Being proactive means you are no longer reacting. Instead, you are anticipating problems before they even occur.
In the fulfillment process, being proactive is vital. After all, there are numerous errors that could arise. Inventory inaccuracies. Inefficient warehouse workflows. Slow shipping transit times. All of these are common problems in the fulfillment process, and you need to be ahead of them at all times. This is particularly true if you want your business to succeed.
So, with that in mind, three ways to become more proactive have been outlined below.
1. Implement Predictive Inventory Management
Inventory problems quickly create a ripple effect throughout the entire operation. If you run out of a popular product, that affects customers. They might be forced to wait or shop elsewhere. On the other hand, carrying too much inventory ties up cash flow and warehouse space.
Predictive inventory management helps. Your business will find the right balance through analysis – analysis of customer buying habits, sales data, and seasonal trends. This way, companies make more accurate forecasts about future demand.
There’s no guesswork either. Predictive tools provide data-driven insights, which help you stay prepared. This allows you to replenish inventory before shortages occur. Plus, you’ll avoid costly overstock situations. The result is smoother operations, better inventory control, and a more reliable experience for customers.
2. Streamline Warehouse Layout and Processes
A warehouse may seem like a straightforward part of the process. But small inefficiencies add up. Fast. Poor product placement. Confusing workflows. Unnecessary employee movement. All of this slows down order fulfillment and increases the risk of mistakes.
Being proactive means regular evaluations of the warehouse. Look at how it operates. Don’t just wait until problems become obvious. Consider whether ordered items are easy to access. Think about where picking routes are optimized. Look at whether employees have the tools they need to work efficiently.
Even minor adjustments lead to improvements. Businesses that review and refine warehouse processes consistently are better equipped to handle growth, seasonal demand spikes, and unexpected challenges.
3. Diversify Shipping and Logistics
Shipping is one of the most unpredictable parts. Weather events. Labor shortages. Carrier delays. Transportation disruptions. Delivery times are impacted by all of these, with little to zero warning.
That’s why relying on a single shipping provider is risky. A more proactive approach is to build relationships with multiple logistics partners. Having alternative options available allows you to adapt quickly when disruptions occur. This also helps to ensure orders continue moving efficiently.
For businesses serving large urban areas, working with specialized providers is a must. Couriers New York, for example, will improve delivery flexibility and speed. The more options you have within your logistics network, the easier it becomes to maintain reliable service when unexpected issues arise.
Conclusion
To conclude, successful fulfillment isn’t just about responding to problems – it’s about preventing them whenever possible. That’s why you need to be proactive. Doing so will improve efficiency and create a better customer experience.
How to Become More Proactive in the Fulfillment Process was last modified: June 1st, 2026 by John Moran
Slow computer networks drain business productivity every single day. Employees waste precious hours waiting for screens to load or applications to respond. Fixing these sudden speed drops requires a clear strategy rather than random guessing.
Simple technical adjustments can transform a sluggish network into a fast machine. Implementing proven methods keeps daily operations running smoothly without unexpected system delays. Businesses save over $5,000 every year by maintaining their systems properly.
Modern Cloud Infrastructure
Many companies move their digital operations away from old on-premise hardware. Finding good cloud computing services provides flexible resources that scale up automatically during peak hours. This shift prevents sudden website crashes when customer traffic spikes.
Virtual setups reduce the need for expensive physical server maintenance. Corporate teams can access files from any remote location instantly. This flexible setup keeps core software stable during heavy work hours.
Cloud platforms provide built-in security features that protect sensitive company files. Businesses save money on hardware upgrades since virtual servers adjust to demand. Scalable infrastructure accommodates growth without requiring new office space.
Smart Data Caching Systems
Repeatedly fetching data from a main database slows down digital applications. A popular engineering guide explains that caching stores frequently used data to reduce response time and backend load.
Temporary storage memory holds items like user profiles or product lists. Local retrieval takes milliseconds instead of seconds. Users experience instant screen updates, which helps keep them happy.
Web browsers use local cache to store images and styling files. Loading a page a second time becomes much faster for the visitor.
Memory Allocation Techniques
System memory needs careful distribution across active programs. Servers crash when single applications hog available space. Allocating strict memory limits keeps background processes under control.
Computer systems run more smoothly when background tasks release unused RAM. Administrators track leaking applications using built-in task manager tools. Cleaning up memory hogs keeps desktop computers responsive all day long.
Restarting servers weekly clears out residual clutter from system memory. This basic practice refreshes data pathways without costing any money. Staff members notice fewer software freezing incidents after a refresh.
Task Automation For Teams
Manual system updates consume valuable hours from technical staff members. An educational blog post shares that automation reduces repetitive tasks, increases system reliability, and frees up time for IT teams. Software scripts handle regular backups and security patches without human intervention.
Removing human error makes digital operations highly predictable. Scheduled maintenance runs during midnight hours to avoid disturbing daily business. Technical experts spend their energy on growing the company instead of fixing repetitive bugs.
Automation routines send instant notifications when errors occur. Support teams fix tiny glitches before users even notice a problem. Running automated checks secures high availability for online storefronts.
Strategic Technology Allocation
Buying top-tier hardware does not solve every performance problem. A university strategic plan notes that a major path towards operational efficiency is optimizing the use of technology in our core services. Aligning digital tools with actual corporate workflows prevents wasting expensive network bandwidth.
Proper management fixes bottlenecks before they impact paying customers. Organizations must evaluate their current tools regularly to clear clutter. Certain key areas require immediate focus:
Software license usage
Server space management
Employee access speeds
Legacy program updates
Spending money on unused software licenses drains company budgets. Auditing user accounts frees up network resources for active team members. Streamlining corporate software improves daily output across all departments.
Hardware And Network Tuning
Physical machinery requires proper configuration to achieve maximum speed. Old router settings, which often limit data flow, need regular adjustments. Updating local firmware clears out communication errors across the workplace network.
Distributing network traffic across multiple channels prevents system strain. Load balancers direct users to the quietest server available.
High-quality cables prevent packet loss during heavy file transfers. Upgrading office wiring from older standards protects data integrity. Fast physical connections support seamless video calls and large downloads.
Routine Performance Monitoring
Problems can develop quietly within complex code setups over time. Tracking memory usage patterns catches resource leaks early. Early detection prevents major system blackouts that cost over $10,000 in lost revenue.
Engineers look at data charts to find weird performance dips. Constant observation tells teams exactly when to upgrade hardware. Regular checkups keep everything stable for long-term use.
Automated alerts sound when processor temperatures climb too high. Cleaning out dust from computer cases prevents thermal throttling. Cool computers run at peak clock speeds without unexpected performance drops.
Maintaining fast computers requires steady effort and smart choices. Small changes in caching, cloud usage, and automated tasks yield massive time savings. Speeding up devices creates a better workplace environment for every worker.
Faster response times keep clients satisfied and protect regular business income. Investing a little time into system maintenance brings major rewards over the coming months. Modern businesses thrive when their technology works perfectly.
Proven Techniques for Better it System Performance was last modified: May 30th, 2026 by Charlene Brown
Sales and ops teams often need fresh data fast. They pull leads from public dirs, track rival prices, or watch job posts for buying signs. Web scraping can fill those gaps, but it also adds risk. A bad scrape can break a site’s rules, trip rate limits, or collect data you should not store.
Many teams also face a second issue. They need that data on phones and tabs, even when they work off line. CompanionLink users know that pain well. If your staff lives in Outlook, Office 365, Google, or a CRM, you need a data path that stays private and keeps working.
Start with a clear data scope, not a tool
Define what you need before you write code. Write down each field you plan to save. Make sure each field has a work use, like name, firm, role, and a work email.
Do not scrape more “just in case.” Extra fields raise risk and add clean up work. You also risk pulling data that you must not store.
Set rules for where the data goes next. Many teams push it to an Outlook folder, then sync it to DejaOffice. Others push it into a CRM, then use CompanionLink to sync to phones by USB, Wi-Fi, or DejaCloud.
Know the rules: site terms, robots, and privacy law
Read the site terms for each source you scrape. Some sites ban bots, even on pages you can view in a browser. If a site bans it, pick a new source or use a paid data feed.
Check robots rules, but do not treat robots as law. Sites use robots to guide bots, not to grant rights. You still need to follow the site terms and your local law.
Privacy rules matter most when you scrape data tied to a person. That includes names, emails, phone numbers, and IDs. Store only what you need, keep a short retention window, and log your source and time of fetch.
Use proxies to keep jobs stable, but keep control
Most blocks happen due to speed and repeat hits. Rate limits protect sites and stop abuse. You should plan slow fetch loops, cache pages, and back off on errors.
Proxies help when you need steady runs across many pages. They spread load and cut hard blocks. Test with one source first, then scale.
Free options exist, but they can add risk. Some log your traffic or reuse IPs that sites already flagged. If you still test one, start with a known list like a free proxy server.
Proxy rules that fit a business team
Pick a proxy type that matches your task. Use data center IPs for price pages that change often. Use home IPs for pages that block data center traffic.
Keep auth keys out of client apps. Put proxies in a server layer you control. That also lets you rotate IPs and set rate rules in one place.
Log each request with source, target, and result. Those logs help when a site changes HTML. They also help if you must prove what you pulled and when.
Move scraped data into Outlook and CRM without exposing it
Scraping often fails at the last mile. Teams dump CSV files into shared drives and hope users import them right. That leads to stale data, mix ups, and odd fields.
Use a tight import path instead. Normalize the data, map fields, and add tags like Source and PullDate. Then write the clean set to Outlook contacts or CRM leads.
CompanionLink fits well here when mobile access matters. Many teams prefer direct USB or Wi-Fi sync for max privacy. Others use DejaCloud when staff work remote and need fast updates.
Keep mobile data private and usable off line
Field teams need data when cell service drops. DejaOffice keeps contacts, cal, tasks, and notes on the device. That cuts the urge to store work data in random apps.
Set device rules like passcodes and lock timers. Sync only the folders your team needs. If a phone goes missing, fast action matters more than fancy tech.
Plan for breakage and support like you mean it
Scrapers break. Sites change HTML, add bot checks, or shift to script heavy pages. You should plan a fix loop, not a one time build.
Write tests that check key fields and row counts. Alert when counts drop or spike. Keep a small set of “gold” pages for fast checks.
Also plan user support. CompanionLink users value clear setup steps and real phone help. Treat your scrape flow the same way. Write a short run book, name an owner, and set a rollback plan for bad imports.
Build a Compliant Web Scraping Flow That Feeds Your CRM Without Leaking Data was last modified: May 30th, 2026 by Adam Brooks
Choosing the right prop trading firm is one of the most consequential decisions a trader makes. The wrong choice can mean delayed payouts, unclear rules, or an evaluation structure that does not reflect how markets actually behave. The right one gives a disciplined trader the tools, capital access, and operational clarity to perform consistently over time.
The number of firms operating in this space has grown significantly. That growth has made due diligence more important, not less. Before committing to a challenge fee or a direct account, traders should know exactly what to evaluate. The criteria below apply specifically to futures prop trading at firms like Hola Prime, where contract mechanics, platform requirements, and drawdown structures differ meaningfully from other markets.
Payout Structure and Processing Speed
The payout system is the most practical measure of a firm's reliability. A firm can offer attractive profit splits on paper, but if withdrawals take days to process or are subject to frequent denials, the value of those splits diminishes considerably.
When evaluating a firm, look for three things: how fast payouts are processed after approval, whether there is a clear policy on denial, and whether the payout system has been independently reviewed. These are not soft differentiators. They directly affect cash flow planning and your ability to manage trading capital across cycles.
Hola Prime publishes payout performance data on its futures platform, including an average payout time of 33 minutes and 48 seconds, and a fastest payout of 3 minutes and 37 seconds. The firm operates a zero payout denial policy and its payout system has been reviewed by Deloitte to validate its reliability and transparency. For traders who have previously dealt with delays and uncertainty elsewhere, that level of documentation matters.
Rule Clarity and Evaluation Structure
Trading rules govern everything from drawdown limits to position sizing and news trading permissions. Complex or poorly communicated rules are a consistent source of frustration for traders, particularly when a breach results in account termination and the rules were ambiguous to begin with.
Before signing up with any firm, request the full trading rules in writing and test your understanding against real scenarios. Pay attention to whether the drawdown is calculated on a trailing basis or a fixed basis, whether there is a daily loss limit, and what consistency requirements apply during the evaluation phase.
Hola Prime's 1-Step Prime Challenge for futures uses a 6% profit target in Phase 1 with no minimum trading days and no daily loss limit. The max trailing drawdown is 4%, with an exception for the $100,000 and $150,000 account sizes where it sits at 3%. News trading is permitted. These parameters are published clearly, and the challenge fee is fully refunded across the first four payouts once a trader qualifies.
For traders who prefer to skip the evaluation entirely, the Direct Account option removes the challenge phase. The consistency requirement is 20% in the Direct Account, compared to 40% during the challenge phase. This flexibility acknowledges that different traders have different preparation levels and risk appetites.
Profit Split and Account Scaling
The profit split percentage determines how much of your performance you actually retain. Most firms advertise headline figures, but the practical split depends on the account type, the evaluation tier passed, and whether any conditions apply.
Hola Prime offers up to 90% profit split on its futures accounts. There are no activation fees and no monthly subscription costs on the futures side, which reduces the overhead a trader carries before generating returns. These terms apply from the outset rather than being unlocked through a scaled progression.
Traders should also consider the range of account sizes available. A firm that caps its funded accounts at a low ceiling limits the practical upside of consistent performance. Understanding the scaling pathway before you begin an evaluation gives you a clearer picture of where your trading could take you over time.
Platforms and Instruments
The trading platform determines execution quality, analytical capability, and the practical experience of managing positions under pressure. A firm that offers limited platform options may not suit traders who have built their process around a specific interface or execution model.
Hola Prime supports three platforms on the futures side: DX Futures, Tradovate, and NinjaTrader. DX Futures is positioned for traders who prioritize speed and execution clarity. Tradovate is built around cloud-based architecture and cross-device synchronisation. NinjaTrader is designed for traders who need advanced analytics and high-performance execution in volatile conditions.
On the instruments side, Hola Prime offers access to over 50 futures instruments across indices and commodities. The breadth of that offering matters for traders who run strategies across multiple asset classes or who want the flexibility to shift focus as market conditions change.
Support, Community, and Transparency
Operational support is often overlooked during the selection process and only felt once something goes wrong. A firm with slow or inaccessible support creates friction at the moments it matters most, including during active trading sessions or when a payout is pending.
Hola Prime provides 24/7 customer support and hosts an active Discord community where traders access daily market commentary, live sessions, and one-on-one mentoring from experienced traders. For traders building discipline over time, that community infrastructure is a practical resource rather than a marketing add-on.
Transparency in pricing is a separate but equally important factor. Execution quality and pricing consistency directly affect profitability, particularly for traders running strategies that depend on tight spreads or precise entry and exit points. Hola Prime publishes daily price transparency reports so traders can benchmark execution quality rather than relying on firm-provided assurances alone.
Making the Decision
No firm is the right fit for every trader. The evaluation structure that suits a systematic futures trader working with indices may not suit someone focused on commodity spreads with a different risk tolerance and time horizon.
The questions worth asking before committing are straightforward. How fast are payouts processed, and is there a published record? Are the trading rules written clearly enough that you could explain them to someone else? What platforms are supported, and do they match your existing workflow? What is the real cost of the challenge once fees, subscriptions, and refund conditions are factored in?
Taking the time to answer those questions against a firm's actual published terms, rather than promotional claims, is the most reliable way to make a decision that holds up once real trading begins.
Trading involves significant risk. Past performance in evaluations does not guarantee results in funded accounts, and traders should only engage with capital and risk levels appropriate to their experience and financial situation.
How to Choose a Futures Prop Trading Firm: What Traders Should Look For was last modified: May 29th, 2026 by Ana Tungdim
Corporate sustainability reporting has moved from annual disclosure exercise to continuous operational discipline. Regulatory timelines are tightening, assurance requirements are rising, and AI is changing how teams collect, validate, and act on sustainability data. The platform you choose now will either support that shift or slow it down.
This guide covers what corporate sustainability reporting software should do in 2026, what separates audit-grade platforms from point solutions, and how to evaluate your options before committing to a multi-year stack.
What Corporate Sustainability Reporting Software Actually Does
Sustainability reporting software centralises the data collection, validation, framework mapping, and disclosure workflows that used to live across spreadsheets, email threads, and disconnected tools.
A capable platform handles Scope 1, 2, and 3 emissions alongside environmental, social, and governance metrics on a single data model. It maps that data to multiple regulatory and voluntary frameworks, including CSRD, IFRS S1 and S2, CARB, TCFD, CDP, and GRI, without requiring manual reconciliation between systems.
The operational reality for most medium and large enterprises is that carbon accounting and broader ESG reporting have been running in separate tools. That separation creates rework, version control problems, and audit risk. When an auditor or regulator asks for evidence behind a disclosure point, a fragmented stack makes that retrieval slow and unreliable.
The right platform eliminates that fragmentation. One data model, one audit trail, one source of truth for both carbon and ESG.
Why 2026 Demands More From Your Reporting Platform
Three shifts are raising the bar for every corporate sustainability reporting software decision right now.
Regulatory scope is widening. CSRD is pulling more companies into mandatory disclosure. CARB is adding US-based and globally operating companies to its California climate disclosure requirements. IFRS S1 and S2 are becoming reference points for investor-grade sustainability disclosure. A platform built around one framework will need constant retrofitting as obligations stack up.
Assurance expectations are hardening. Every data point needs traceable inputs, documented methodology choices, and a clear approval path. Platforms without that governance architecture built in will create significant audit preparation overhead.
AI is entering sustainability workflows at every level. Teams are using AI assistants to draft reports, complete questionnaires, surface data gaps, and prepare board briefings. The platforms that win in this environment are not necessarily the ones with the most AI features inside them. They are the ones that provide validated, audit-grade sustainability data that AI assistants can act on with confidence.
What Separates Audit-Grade Platforms From Point Solutions
The corporate sustainability reporting software market includes a mix of audit-grade platforms built for enterprise complexity and AI-native point solutions built primarily around carbon accounting or a single use case.
Audit-grade platforms are designed so that every workflow, every data input, and every AI-supported feature sits inside a governance layer. That means traceable inputs, evidence capture, approvals, and a complete audit trail. When assurance providers or regulators review disclosures, the evidence is already structured and retrievable.
Point solutions, including many AI-native carbon platforms, can produce fast outputs and attractive interfaces. What they cannot replicate is the accumulated context that builds inside an enterprise-grade platform over years of use: multi-entity methodology choices, supplier-level Scope 3 data, framework mapping intelligence, reviewer overrides, and targets-and-progress history. That context is what makes AI outputs trustworthy rather than merely plausible-looking.
For a structured comparison of leading platforms including their framework coverage, AI capabilities, and audit readiness, the KEY ESG guide to corporate sustainability reporting software covers the top options with enough detail to support a shortlisting decision.
Five Evaluation Criteria for Corporate Sustainability Teams
When assessing platforms, corporate sustainability teams should apply five criteria that go beyond feature checklists.
Unified carbon and ESG on one data model. Scope 1, 2, and 3 emissions should live in the same system as your environmental, social, and governance metrics. Platforms that handle carbon separately from ESG create reconciliation overhead and audit risk. Ask vendors specifically whether carbon and ESG share a data model or sit in integrated but separate modules.
Multi-framework architecture. Your reporting obligations will not stay static. A platform that handles CSRD today but requires reimplementation for IFRS S1 and S2 tomorrow is not a long-term solution. Look for a single data model that maps across frameworks simultaneously, so the same underlying data answers different disclosure requirements without manual rework.
Audit trail and evidence management. Every data point should carry its source, methodology, approval history, and any reviewer overrides. This is not optional in an assurance environment. Ask vendors to show you what an auditor sees when they review a disclosure prepared on the platform.
AI readiness, not just AI features. There is a meaningful difference between a platform with AI features and a platform whose data is ready to be used by AI. The most useful capability in enterprise sustainability software right now is the ability to connect your preferred AI assistant directly to your validated sustainability data. KEY ESG's MCP connector does exactly this: read-only, secured via Auth0 authentication, scoped to your organisation's data, with no exports and no credential sharing.
Teams can run reports, complete questionnaires, and prepare briefings in the AI tools their organisation already uses, whether that is Claude, ChatGPT, Mistral, or Cursor, without learning a new in-platform AI and without compromising audit defensibility.
Scalability for multi-entity and multi-jurisdiction complexity. Enterprise sustainability reporting rarely involves a single entity reporting in a single jurisdiction. Platforms should handle unlimited entities, sites, and organisational structures without requiring separate instances or manual aggregation.
The AI Question Every Sustainability Team Should Be Asking
AI is now a procurement consideration in sustainability software, not just a feature on a marketing page. The question is not whether a platform uses AI. The question is whether the platform's data is good enough for AI to act on safely.
AI assistants are only as useful as the data they query. Validated, audit-grade sustainability data produces outputs that can go into board briefings, investor reports, and regulatory submissions. Unvalidated or fragmented data produces outputs that require manual checking before they can be used, which defeats the efficiency argument for AI adoption.
KEY ESG embeds AI directly inside the platform for data validation and anomaly detection, flagging outliers, unit mismatches, and consistency issues during data ingestion and review, all under reviewer oversight and with a full audit trail. Through the MCP connector, that same validated data is also available to the AI tools your organisation has already adopted across the business. The result is AI that accelerates sustainability workflows without removing the human approval and assurance layer that disclosure-grade outputs require.
The platforms that earn a place in enterprise sustainability stacks in 2026 will be the ones that treat audit-grade data as the foundation for AI, not a constraint on it.
Building a Shortlist
Start by mapping your current reporting obligations and the frameworks you expect to add over the next three years. Then assess which platforms on your shortlist can handle that scope without reimplementation.
Prioritise platforms that give you one data model for carbon and ESG, a complete audit trail, and genuine AI readiness through open standards like MCP. Evaluate total cost including the overhead of running parallel tools, not just licence fees.
For a starting point on the shortlist, the KEY ESG guide to corporate sustainability reporting software covers the leading platforms with detail on framework coverage, AI capabilities, and enterprise readiness.
The right platform reduces reporting overhead, strengthens audit defensibility, and positions your team to use AI safely as workflows continue to evolve. That combination is what separates a long-term infrastructure decision from a tool you will need to replace in two years.
Corporate Sustainability Reporting Software: How to Choose the Right Platform in 2026 was last modified: May 29th, 2026 by Ana Tungdim
Finding experienced .NET developers in the U.S. has never been harder. Demand for engineers who specialize in ASP.NET Core, Blazor, and Azure-backed systems is outpacing local supply — and salaries reflect that. For many companies, building and keeping a full in-house team simply isn't the most practical path forward.
That's why more U.S. businesses are turning to net software outsourcing as a real strategic option, not just a cost-cutting measure. When done right, it gives you access to senior-level talent, faster project timelines, and the flexibility to scale without the overhead of permanent hires.
If you're evaluating whether to outsource your next project, this guide walks you through the key signals that it makes sense, what to look for in a vendor, and the mistakes most companies make the first time around. If you're already decided and want to move quickly, it's worth checking out dot net development outsourcing as a starting point for vetting specialized providers.
When Does Outsourcing .NET Development Actually Make Sense?
Not every situation calls for outsourcing. But there are four scenarios where it consistently makes more sense than trying to hire in-house.
You don't have the internal expertise. If your roadmap requires ASP.NET Core microservices, .NET MAUI for cross-platform apps, or Azure Service Bus integrations, and your current team doesn't cover those areas — outsourcing gives you that capability without a six-month recruiting cycle.
You're working against a deadline. Hiring a full-time engineer takes three to four months on average, from posting a job to a productive first sprint. An established outsourcing partner can typically have a team oriented and working within two weeks.
Headcount doesn't fit your budget. A mid-level .NET developer in the U.S. costs $130,000–$160,000 per year in salary alone — before benefits, equity, and overhead. For project-based work or scaling up temporarily, outsourcing lets you pay for what you actually need.
Your workload isn't consistent. If you have a product launch coming up, a major migration, or a feature-heavy quarter followed by maintenance mode, a dedicated outsourced team can expand and contract around your actual demand rather than sitting idle between peaks.
One clarification worth making here: outsourcing and outstaffing are not the same thing. Outsourcing means handing a function or project to an external vendor who manages delivery. Outstaffing (or staff augmentation) means renting individual developers who work under your direct management. Both are valid, but they solve different problems. This guide focuses on outsourcing — where the vendor owns the process.
What You Actually Gain From .NET Outsourcing
The obvious benefit is cost savings, but that's usually not the most important one.
Access to specialists you can't easily hire. Engineers with deep experience in gRPC, SignalR, Entity Framework optimization, or .NET on Azure aren't easy to find locally. Outsourcing vendors who specialize in the Microsoft stack maintain pools of these specialists across multiple time zones.
Faster time to start. A vendor with established processes — project templates, code review workflows, CI/CD pipelines already in place — can begin productive work far faster than a newly assembled in-house team still figuring out its norms.
Reduced operational risk. When a developer leaves your in-house team, you feel it immediately. With an outsourcing partner, team continuity is their problem to manage, not yours. The same applies to keeping up with .NET version upgrades and tooling changes.
Predictable spending. Whether you're on a fixed-price contract or a time-and-materials arrangement, outsourcing makes it easier to plan your quarterly spend than the variable costs of employment.
That said, outsourcing isn't without tradeoffs. Communication overhead is real, especially across time zones. IP protection requires a well-drafted NDA. And quality control depends entirely on how well you define requirements upfront. Knowing these risks going in makes them manageable.
5 Criteria for Choosing a .NET Outsourcing Partner
This is where most decisions go wrong. Companies either move too fast or focus on the wrong signals. Here's what actually matters.
1. Relevant technical depth. Ask specifically about experience with the .NET version your project requires — not just ".NET" in general. .NET 8 and .NET 9 have meaningful differences from .NET Framework 4.x. Verify experience with your target deployment environment (Azure, AWS, on-prem), your preferred database stack, and your CI/CD tooling.
2. Portfolio that matches your context. A vendor with 50 developers but no experience in your industry or project type is a riskier bet than a smaller team that's built similar systems. Ask for case studies — not just logos — that describe the technical challenge and how it was solved.
3. Process and visibility. You should know what's happening at all times without having to chase updates. Look for vendors who work in structured sprints, provide weekly written updates, give you direct access to the code repository, and have a defined escalation path when something goes wrong.
4. Communication overlap. For U.S.-based companies, a partner in Eastern Europe or Latin America typically offers four to six hours of same-day overlap with U.S. business hours. That's usually enough. Fewer than three hours of overlap makes real-time collaboration painful and slows down decisions.
5. Contract model that fits your project type. Three models are common in outsourcing .NET development:
Model
Best for
Watch out for
Fixed Price
Well-defined scope, limited changes expected
Scope creep adds cost quickly
Time & Materials
Evolving requirements, ongoing work
Requires active oversight to manage spend
Dedicated Team
Long-term product development
Needs a strong internal point of contact
Before signing with anyone, run a paid discovery phase or small test project. Any legitimate vendor will agree to this, and it tells you far more than a sales call.
Three Mistakes That Derail .NET Outsourcing Engagements
Choosing on price alone. The cheapest outsourcing bid almost always reflects either junior developers, under-scoped work, or both. You'll pay the difference later in rework, delays, and accumulated technical debt. A reasonable mid-range vendor is nearly always a better investment than the lowest quote.
Starting without proper documentation. Vague requirements handed to an external team produce vague software. Before your outsourcing engagement begins, you should have: user stories or functional specs, wireframes or design references where applicable, agreed-upon tech stack, and clear acceptance criteria for each deliverable. The vendor can help you create this, but you need to drive it.
No internal owner. Outsourcing doesn't mean handing off responsibility entirely. Someone on your side needs to be the decision-maker — available for questions, reviewing deliverables, and unblocking the team when requirements shift. Without that person, work stalls and misunderstandings compound.
What the Contract Should Cover
Once you've chosen a partner, don't rush the agreement.
Intellectual property. The contract must explicitly state that all code, documentation, and assets become your property upon payment. Don't assume this is standard — verify it clause by clause.
Confidentiality. A mutual NDA should be signed before any business information or technical details are shared. This includes both project specifics and any proprietary processes you discuss during scoping.
Service level expectations. Define what "on time" means, how bugs are classified and prioritized, what the response time commitment is for critical issues, and what the remediation process looks like when something is missed.
Exit terms. Understand what happens if the relationship doesn't work out. You should have access to all code and documentation at any point, and transition assistance should be written into the contract, not treated as a favor.
Outsourcing .NET development works — but only when you treat it as a managed partnership rather than a hands-off transaction. The companies that get the most value from it go in with clear requirements, choose a vendor based on capability rather than cost, and stay engaged throughout the process.
If your team is stretched thin, your timeline is pressing, or you're trying to build something that requires expertise you don't currently have, net software outsourcing is a practical path worth taking seriously. Start by evaluating two or three vendors, run a small paid test, and make your decision based on what you see — not what they tell you in the pitch.
.NET Outsourcing Guide 2026: Criteria, Costs & Pitfalls was last modified: May 29th, 2026 by Evelina Brown
When you order something online, the excitement is often mixed with a little anxiety: Will it arrive on time? Will it get lost? A decade ago the only way to find out was to call the store and wait on hold. Today most packages come with a tracking number, and for many shoppers that little code is more reassuring than a friendly voice on the phone. In fact, surveys show that being able to track an order is now one of the main reasons people choose one retailer over another, and many shoppers say they would even switch to a different seller if tracking wasn’t available.
The rise of transparent delivery
Package tracking began as simple barcode scans that told warehouse workers when a parcel changed hands. Now those scans feed realtime updates to websites and phone apps. Customers watch as their order leaves the warehouse, passes through sorting hubs and boards a delivery van. During the pandemic, this level of detail became the norm; shoppers got used to knowing exactly where a package was and when it would arrive. Research into delivery experiences found that poor communication and the inability to track an order were among the biggest reasons customers felt let down. Many people couldn’t track their most recent delivery and wished they had more frequent updates. When tracking works well it offers something support agents often cannot: a sense of control.
Trust, anxiety and peace of mind
Modern parcel theft and “porch piracy” have made people anxious about leaving packages unattended. Realtime tracking helps by narrowing the delivery window. People can schedule their day around a “out for delivery” notification instead of sitting by the window waiting for a van. This immediate feedback loop builds trust. Customers know if a shipment gets delayed or rerouted, because the tracker tells them. They don’t have to call a busy support center and hope for an update; they can see the status themselves.
A generation raised on selfservice
People increasingly prefer to solve problems on their own. Studies show that most customers would rather resolve an issue independently before contacting a representative. Unfortunately, many support systems are still plagued by long wait times, confusing menus and unhelpful answers. Even when self service tools exist, they can be poorly designed or incomplete. Tracking stands out as a rare self service tool that works smoothly. It answers the simple question “Where is my order?” without forcing the user through a maze of menus or chatbots.
Global shopping and cultural differences
Tracking has also opened the door to shopping from abroad. When customers buy from overseas sellers, there’s no convenient call centre in their own time zone. Surveys in multiple countries have found that the ability to track a delivery encourages people to shop internationally. Instead of worrying about customs delays or language barriers, shoppers can follow their parcel across borders and feel confident it hasn’t gone missing.
Beyond simple notifications
Tracking tools are becoming smarter. Some carriers send text messages when a package is a few stops away. Others integrate with smart speakers and doorbells, announcing deliveries out loud. Apps can even estimate arrival times based on traffic and weather. These features make tracking feel less like a utility and more like a service in its own right.
Stories that resonate
Ask anyone who frequently shops online and they’ll have a tracking story. A busy parent might coordinate nap time around a delivery, avoiding the dreaded missed parcel slip. A traveler shipping souvenirs home can watch the box clear customs and know it arrived safely before they return. These experiences show why customers value independence and clarity more than scripted apologies.
Finding a trusted source of updates
People still need customer support for returns or complex problems, but for day today shipping questions, tracking wins. Robust tracking platforms let shoppers check status across multiple carriers, domestic and international, without juggling different websites. For example, anyone looking to follow several parcels at once can check here trackingpackage.com to see updates from various logistics systems in one place. This kind of convenience keeps shoppers informed without the frustration of long waits or confusing support scripts.
The future of the delivery experience
As online shopping continues to grow, transparent delivery will remain critical. Shoppers expect more than a vague “3–5 business days”; they want regular updates, accurate arrival estimates and quick explanations when something goes wrong. Businesses that invest in clear, reliable tracking earn trust and reduce the burden on their support teams. In a world where nearly every product can be ordered online and shipped globally, providing dependable tracking isn’t just a nice extra—it’s becoming a basic expectation. By combining modern tracking tools with customer friendly policies, retailers can deliver a smoother experience and build loyalty across borders.
Why Customers Trust Package Tracking More Than Customer Support was last modified: June 4th, 2026 by Thomas Lore
OTT is emerging as one of the most performance-sensitive segments in the digital market environment. The current streaming users demand a seamless playback experience without buffering, lagging, and other issues on all kinds of devices.
For OTT providers, even minor service issues can affect customer retention, ad monetization, watch time, and overall company reputation. With streaming competition intensifying, availability has now shifted from a back-end issue to a key business priority.
This is where DevOps and SRE revolutionize OTT development processes.
The frameworks are enabling streaming services to scale their applications, manage their infrastructures, deploy quickly, and achieve predictable performance even when traffic levels are unpredictable.
With global video data consumption soaring alongside the adoption of 4K/8K streaming and localized edge-computing, infrastructure demands have reached unprecedented levels.
What is the significance of reliability in OTT development?
Modern OTT platforms work under very volatile conditions, whereby traffic can change within seconds. The broadcasting of a live sports finale, an important product launch, or entertainment content can cause a sudden influx of millions of concurrent viewers.
Therefore,OTT platform development goes well beyond merely developing the streaming application. Modern OTT architecture demands:
Real-time observability: Tracking video-specific metrics like EBVS (Exit Before Video Start) and VMAF (Video Multi-Method Assessment Fusion) scores.
Automated deployments: Using automated blue/green or canary testing environments to update playback features without interrupting active viewers.
Multi-CDN & Scalable infrastructure: Dynamic traffic routing to switch seamlessly between Content Delivery Networks when one experiences localized congestion.
Incident management: Rapid failover protocols for live video origin servers.
How does DevOps accelerate OTT innovation?
OTT providers continuously innovate with feature rollouts, recommendation engine updates, advertising functionality, payment system upgrades, and device compatibility adjustments. A manual approach to dealing with these challenges leads to operational difficulties, not to mention increased chances of service disruption.
DevOps ensures the ability to deliver updates to an OTT platform quickly without impacting its stability. The Continuous Integration/Continuous Deployment (CI/CD) processes facilitate smoother deliveries of updates and decrease potential periods of platform downtime and playback issues.
By utilizing Canary Deployments, DevOps teams can push a new feature, such as a revamped recommendation engine or UI update, to just 1% of active users, validating stability before rolling it out globally.
The most significant operational benefits of DevOps are:
Increased deployment speed
Decreased failure rate of updates
Greater infrastructure consistency
Easier scalability management
Automatic testing and monitoring processes
According to research conducted by Google Cloud through its DORA studies, organizations that have adopted mature DevOps practices have been shown to exhibit fast deployment speeds and have very quick recoveries
Why is SRE critical for streaming platforms?
Whereas the DevOps culture revolves around agility and operation-based collaborations, Site Reliability Engineering (SRE) revolves around scalability and reliability.
SRE involves applying the concepts of software engineering to operations and infrastructure management. The objective is to ensure reliability despite any level of heavy traffic by ensuring predictable performance.
In contrast to legacy operations, the SRE model bridges the gap between development and operations through strict Service Level Objectives (SLOs) and Error Budgets. If a deployment introduces buffering that consumes too much of the allowed Error Budget, the SRE framework halts further releases, mathematically balancing fast innovation with platform stability.
The role of automation and real-time monitoring in OTT platforms
With today’s modern OTT infrastructures, an incredibly large amount of data is generated every second. Manually monitoring such environments is not feasible, particularly when it comes to platforms that run across different geographical regions.
As a result, there has been a significant increase in the implementation of sophisticated observability solutions using AI and machine learning technologies.
Real-time telemetry, distributed tracing, predictive analysis, and intelligent monitoring are among the essential practices being used by the current generation of streaming services for early detection of potential infrastructure issues.
For Netflix, pioneering Chaos Engineering (via tools like Chaos Monkey) proved that intentionally causing infrastructure failures during off-peak hours is the most effective way to build a resilient, self-healing streaming ecosystem.
Cloud-native architecture and OTT scalability
Today, cloud-native solutions are considered an integral part of OTT development. Platforms that use microservices architecture, Kubernetes orchestration, and container-based infrastructure to scale easily during periods of peak traffic are unmatched in terms of their capability.
Since DevOps and SRE approaches focus heavily on automation and scalability, they align perfectly with cloud-native solutions. This allows OTT platforms to adapt easily by using Kubernetes orchestration to automatically scale containers and add computing power the moment traffic increases. Additionally, using a microservices architecture decouples different platform systems. This ensures that even if one component like the payment gateway fails under heavy traffic, the actual video playback experience remains completely unaffected.
Another advantage of cloud-native architecture is that it enhances redundancy and disaster recovery capabilities, which are becoming more critical as global streaming platforms cater to audiences from different regions of the world.
Value of DevOps and SRE for businesses
DevOps and SRE not only contribute to enhancing efficiencies but also influence customers' experience, further driving sales and scaling the platform.
Efficient delivery can lead to:
High user retention
Higher numbers of viewing time
Higher advertisement completion rate
Trust among the audience
Better brand image
This is especially true for businesses working in highly competitive streaming environments.
Summing up
With the increasing complexity of OTT ecosystems, DevOps and SRE have become necessary components in the OTT world.
While DevOps enables more innovative and agile deployment capabilities, SRE is all about reliability and resilience. Together, they make it possible for OTT players to create robust ecosystems capable of meeting all the requirements of streaming platforms.
All of this means that in 2026, successful streaming will depend on content quality as well as operational excellence.
The Role of DevOps and SRE in OTT Platform Performance was last modified: May 29th, 2026 by Julia Haynes
Whether you’re excited or peeved by it, chances are you’re using AI at work in some shape or form already. But, are you taking full advantage of the tools on offer, or are you still stuck on the basics? Here are six ways you can improve your AI game at work without sacrificing accuracy, critical thinking, or agency.
Write Better Prompts
People’s experience of using AI is directly proportional to the time and effort they spend on crafting prompts. Sure, an LLM will write a project update out for you when asked, but being vague guarantees mediocrity.
Always provide as much detail as you can to make prompts shine. Set the tone. Define your audience. Establish structure and constraints. This might take longer to set up, but it results in detailed prompt templates you can reuse to save much more time in the long run.
You can go a step further by having the AI cover different angles. Let it point out flaws in a sales pitch that might be obvious to a leery customer. Or, have it find and challenge assumptions you yourself might not be aware of.
Make It a Core Part of Your Workflow
People new to using AI in the workplace assume it’s a tool like any other and reach for it as needed. While that can still take a load off, it’s not as efficient as setting up workflows that work in your favor quietly, in the background.
Let’s say you frequently have to sit through meetings. You could use an all in one AI platform to set yourself an AI agent that transcribes the meeting, creates cliff notes, identifies needed follow-ups, and presents them for your approval each time. On the other hand, teams are finding AI useful in maintaining up-to-date project summaries and developing onboarding materials for new members.
Of course, all of this needs to be done responsibly. On the one hand, this means assuming personal responsibility and using AI both ethically and in ways that don’t expose or endanger sensitive information. On the other, companies themselves need to create a supportive environment. Policies should clearly identify who can use which AI tools for what purpose while building a culture that champions transparency and provides adequate training for optimal AI use.
Go Beyond Summarizing
Having an AI give you the gist of that 200-page legal document is already a massive time-saver, but it’s crude in comparison to the benefits you get if you take it up a level.
Next time, instead of just asking for a neutral summary, have the AI point out key risks or conflicts mentioned, or let it lend an analytical hand by highlighting the decisions this information lets you make. Better yet, you can compare multiple documents and sources and have the AI look for recurring themes, discrepancies, or other factors browsing manually would have surely missed.
You can also put your newfound prompting skills to use here. Create tailored summaries based on needs and stakeholders. Your manager, the CEO, and a customer might all be interested in a project you’re working on, but the information each would find most useful can differ drastically.
Up Your Brainstorming Game
Best AI assistants come up with brilliant ideas so that you can refine them. This is another staple people are underutilizing. Giving you a list of titles or content ideas is nifty, but it’s a spark more than a storm.
Rather than just create ideas, have the AI fight for them or play devil’s advocate to your inputs. Or, present the AI with an idea and have it evaluate that idea from the point of view of an investor or compliance manager. There’s nothing wrong with dreaming big, but AI’s real brainstorming power comes from creating actionable ideas that remain feasible despite actual real-world limitations.
Smarter Task Automation
Automation is regularly one of the first things people try with AI. Success is immediate, so few bother to go past having their AI fire off appropriate responses to generic emails or insert the right Excel formula every time.
Leveling automation up involves identifying processes that are straightforward, repetitive, and easy to verify, and then stringing them together. The comprehensive meeting assistant discussed above is a good example, and so is using AI to review contracts or regularly extract shifts in customer sentiment from new reviews.
Review What the AI Puts Out
While not inevitable, complacency has become a common consequence of the push for greater AI integration. LLMs in particular are prone to presenting everything from facts to gibberish with the same polished confidence.
[A close-up of a vintage typewriter with ‘Write something’ typed on paper.]
You are signing off on the work, so you should always have the final say. Treat AI outputs like the drafts that they are. Take the time to validate any facts and figures or create adjustments if the tone doesn’t quite fit your audience. Also, don’t be afraid to enlist an AI’s help in identifying which parts of the output might be suspect.
Tips and Tricks for Using AI Better at Work was last modified: May 29th, 2026 by Julian Felix
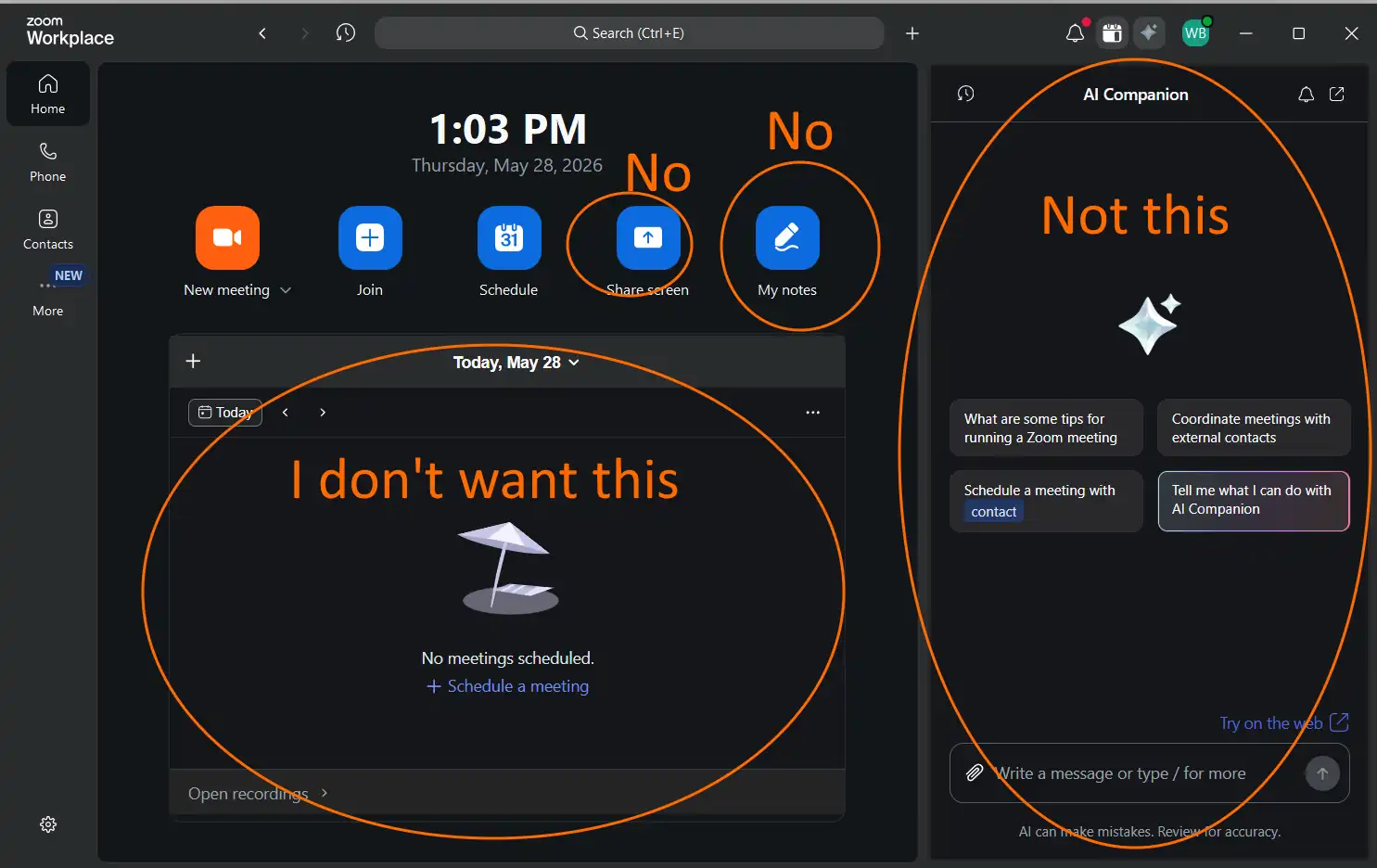
The latest Zoom update features an AI ad with no setting to remove it. This is spammy corporate nonsense. Here’s a guide to try to banish it forever.
Zoom in 2019 was simple. You joined a meeting. That was it. Since then Zoom has added a calendar nobody asked for, a notes panel, a phone tab, and now an AI Companion ad that takes up a full sidebar. Two months ago the Notes button showed up and pushed the useful buttons off screen. None of this comes with a straightforward off switch.
The AI Companion panel is the worst offender so far. The panel parks itself on your home screen. The same panel fills your daily view. Zoom even hard-coded a tooltip in some versions that reads “AI Companion always shows on the home screen.”
Paying customers have no obvious way to remove the panel from inside the app. The off switch hides in the web portal, buried under account settings most users never touch.
Here is how to find it.
For Individual Users
The desktop app will not save you here. The setting lives on the Zoom website. Open a browser and follow these steps.
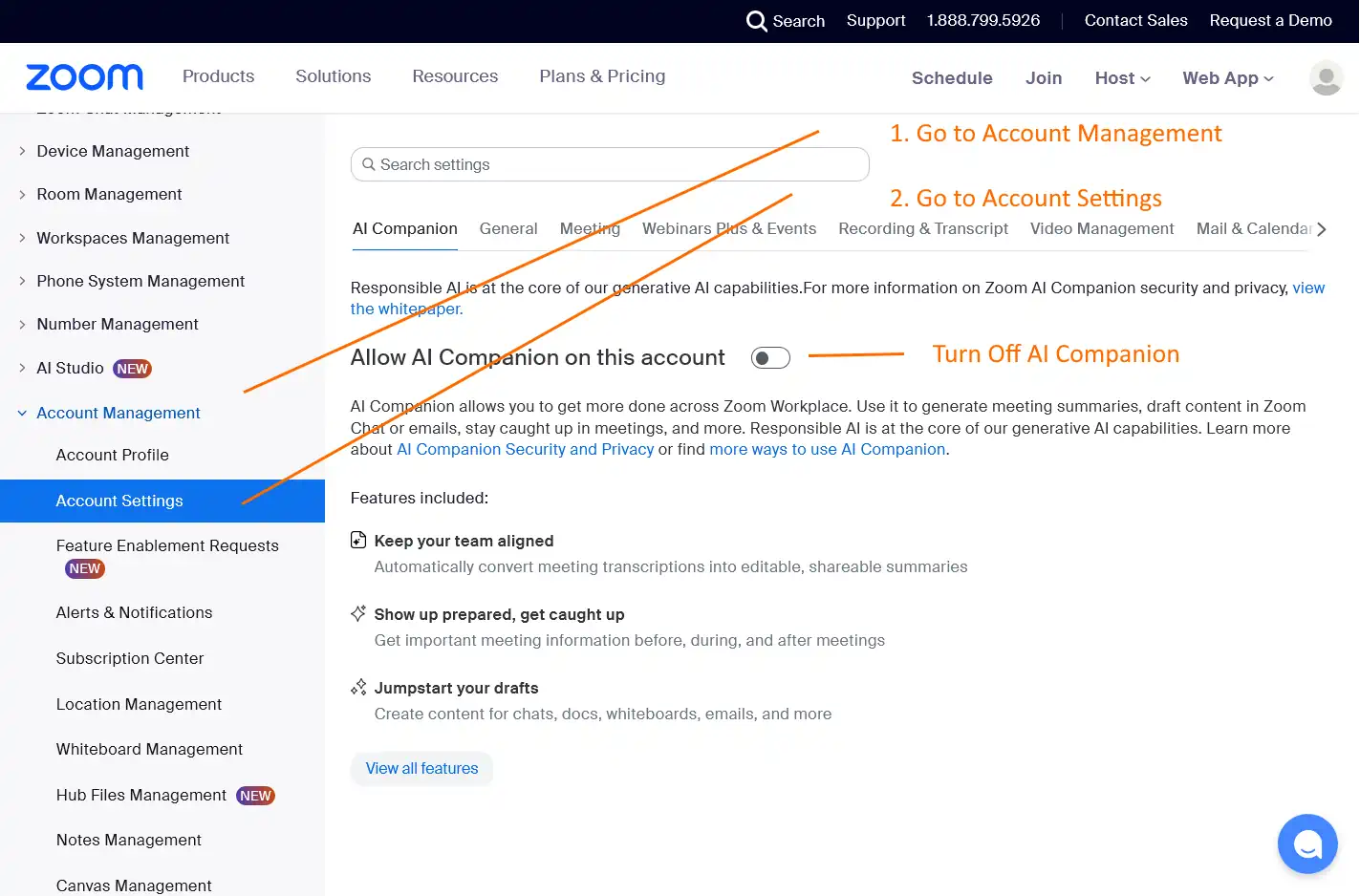
Step 1 – Get to the AI Companion settings:
Go to zoom.us and sign in
Click your account icon at the top right
Select My Account
Click Settings in the left panel
Choose the AI Companion tab
Step 2 – Kill the panel:
Two toggles wait on that page. The first toggle disables AI Companion as a feature. The second toggle removes the AI Companion panel from the Zoom Workplace sidebar. Switch both off. Save the changes. Quit Zoom and relaunch the app.
The panel should be gone from your home screen and daily view.
If you prefer to start from inside the desktop app:
Click your account icon at the top right
Choose Settings
Select My Account
Click View Advanced Features
Zoom opens a browser and drops you into the web portal. From there follow Step 1 and Step 2 above.
A note for free account users: Some free users report that the AI Companion toggles do not appear inside the desktop app. Skip the app entirely. Go straight to zoom.us in a browser and run both steps from there. Reports are mixed on whether free accounts can remove the panel at all. The web portal gives you the best shot.
For Meeting Hosts
You can disable the AI Companion for a specific meeting before the call starts. Go into your meeting settings and switch the feature off for that session. During a live meeting, a small icon sits in the top right corner. Participants can tap that icon to ask the host to turn the AI Companion off. The host holds all the power here. Guests cannot force the switch themselves.
For IT Admins
If you manage a company Zoom account, the panel may be enabled at the account level. Personal settings cannot override account-level settings. Users under your account cannot fix this themselves. You need to go in and kill the panel for everyone.
Your admin locked the setting on. No personal fix exists for this. Contact your Zoom administrator and ask for the panel to be disabled at the account level.
Zoom re-enabled it after an update. Many users report this happening silently. Go back through the web portal steps and toggle the panel off again. Admins should lock the setting after every change.
It may not be Zoom’s panel at all. Third-party tools like Otter and read.ai join meetings through Zoom’s SDK and show up as AI companions. If the panel looks slightly different, or keeps appearing even after your Zoom settings are off, a third-party app may be the real culprit. Check here:
Open Account Settings
Click Apps
Remove any apps you do not recognize
Also go to Account Settings, open Meetings, and switch off “Auto-join all meetings.” That stops outside bots from crashing your calls uninvited.
You are still seeing a pop-up to enable AI Companion. Make sure you toggled the feature off in both the desktop app and the web portal. One alone may not be enough. Some users also report that a newer Zoom build quietly fixed the home screen ad without any settings change. Updating Zoom is worth trying if nothing else works.
What You Cannot Remove (Yet)
The AI Companion panel is fixable for most users. The calendar and the Notes clutter are a harder fight. Zoom has not provided a way to hide the daily calendar view from the home screen. The Notes button landed a couple of months ago and Zoom offers no toggle to remove it. These features shrink the space available for the buttons people actually use.
For now the web portal fix handles the worst offender. The AI Companion ad can go away. The rest of the clutter is still a work in progress.
Frequently Asked Questions
Can I get rid of the AI Companion on Zoom?
Yes, but the switch is not in the desktop app. You need to log into zoom.us, go to Settings, and find the AI Companion tab. Two toggles sit there. Turn both off. Restart Zoom.
How do I edit AI Companion settings in Zoom?
Log into zoom.us. Go to Settings, then the AI Companion tab. All controls live there. The desktop app does not show the full settings.
How do I disable Zoom Notetaker?
Zoom Notetaker is a separate feature from AI Companion. To kill it, log into zoom.us, go to Settings, and look for the Notetaker section. Toggle it off there.
How do I remove AI bots from Zoom meetings?
If a bot is joining your meetings uninvited, it may be a third-party tool like Otter or read.ai, not Zoom’s own AI Companion. Go to Account Settings, open Apps, and remove anything you did not install. Also go to Meetings settings and turn off “Auto-join all meetings.”
How do I get my Zoom back to normal?
There is no single reset button. The AI Companion panel, the calendar, and the Notes clutter all have separate settings buried in the web portal. This article covers the AI Companion ad. Zoom has not provided a way to hide the calendar or the Notes button yet.
Why does Zoom have an AI Companion?
Zoom wants to sell AI features. The AI Companion panel is advertising for a paid add-on. Zoom makes it hard to remove because the company wants you to use it.
How to Remove the Zoom AI Companion Ad (Home Screen and Daily View) was last modified: May 28th, 2026 by JW Bruns
Quantum computing has stumbled against one crippling wall for decades. Quantum bits disintegrate rapidly. Information vanishes within microseconds. Errors multiply faster than any machine can repair them. This flaw has trapped quantum processors inside research labs.
That wall just crumbled. Artificial intelligence has cracked quantum error correction at the breakneck pace quantum machines demand. The development rewrites the rulebook. The computing world now teeters on the brink of two separate hardware eras. AI-hungry classical chips arrive first. Quantum processors with AI correction woven into their core follow second.
The Error Correction Breakthrough That Changes Everything
Quantum machines inhabit a realm where data evaporates almost immediately. A quantum bit may preserve its condition for merely 100 microseconds. Thousands of glitches strike every second during a single operation. The system must catch and mend these flaws faster than fresh ones materialize.
Conventional computing cannot match that tempo. Classical correction methods lag hopelessly behind. Decoding what failed consumes milliseconds. The quantum condition has already disintegrated by then. The operation vanishes.
AI transformed the mathematics. Machine learning frameworks now decode quantum glitches in less than one microsecond. NVIDIA’s GB300 GPUs execute correction cycles in real time. They examine the quantum condition, pinpoint errors, and push fixes back before the information rots.
This transcends theory. IBM is constructing a real-time AI error correction decoder for 2026 rollout. The design employs classical AI processing as a live runtime companion. The quantum chip generates readings. The AI silicon decodes them instantly. Fixes stream back in an unbroken cycle.
The perspective has pivoted across the entire discipline. A quantum machine lacking an AI correction framework cannot sustain operations. The two technologies must function as a unified apparatus. This truth propels the next ten years of hardware evolution.
Generation One: AI-Native Classical Chips Arrive First
The first hardware epoch has already landed. These are classical chips where AI processing is not grafted on as a bonus feature. AI capability is etched into the silicon from conception.
AMD’s latest moves demonstrate the pattern. The firm inked a contract with OpenAI for up to six gigawatts of Instinct GPU capacity. Their XDNA blueprint weaves neural processing units straight into CPUs. The MI500 roadmap pledges 1,000 times the AI muscle of current MI300X chips by 2027.
This is not gradual refinement. The shift represents a core architectural upheaval. AI processing claims first-class hardware status. The chip handles machine learning tasks the same way memory access or graphics rendering gets handled.
These AI-native chips fulfill twin roles. They satisfy today’s machine learning appetites. They also construct the classical control layer for tomorrow’s quantum assemblies. AMD and NVIDIA are both framing their AI silicon as the control plane for quantum chips.
The funding wave mirrors this passage. Firms are funneling billions into AI-specific hardware right now. They recognize quantum computing will not reach industrial scale for several more years. But they also grasp that the AI chips they forge today will become the error correction motors for quantum assemblies tomorrow.
Generation Two: Quantum Chips With AI Built In
The second wave fuses both technologies into a unified system. Quantum processors couple with specialized AI correction hardware on matching silicon or within shared cryogenic chambers.
The blueprint exists already. A quantum processor spits out millions of syndrome measurements every second. These measurements pinpoint error locations. An AI chip nestles beside the quantum hardware. The chip ingests raw syndrome data and decodes it instantly. Decoded corrections loop back into the quantum processor within microseconds.
Speed determines survival. If the AI correction system hesitates, the quantum information vanishes. The entire calculation collapses. The hardware must function as one locked-in unit.
Multiple companies are constructing toward this vision. IBM’s roadmap for late spring includes quantum processors engineered to mesh with real-time classical decoders. Rigetti and IonQ are investigating parallel architectures. The objective stays consistent everywhere. Position AI processing as near to the quantum hardware as physical law permits.
The timeline for fault-tolerant quantum machines now spans roughly half a decade. Industry observers flag the window from late this decade through early next as the period when error correction hits the threshold required for practical computation. Forrester forecasts practical quantum computing by the end of this decade. That forecast hinges on AI-driven error correction succeeding at volume.
Why The Two-Generation Model Matters
The industry refuses to wait for quantum perfection. Companies are constructing the classical infrastructure quantum will demand right now. AI-native chips train the algorithms. They sharpen the error correction models. They forge the architectural patterns that will migrate to hybrid quantum-classical systems.
This strategy minimizes exposure. Companies can pour resources into AI hardware today and capture immediate value. Those identical chips become the bedrock for quantum systems later. The shift unfolds gradually rather than abruptly.
The two-generation framework also establishes a transparent technology route. Engineers understand the next milestone. They cultivate AI processing capabilities first. They tune for minimal latency and maximal throughput. Then they weave those capabilities into quantum hardware once the physics ripens.
The Timeline Is Accelerating
Recent breakthroughs have squeezed the development schedule. Google’s Willow processor revealed exponential error suppression in late last year. Quantinuum achieved matching results with trapped ion systems. These were not modest gains. They were validation that scaling quantum error correction genuinely functions.
The discipline has breached a critical boundary. Error rates are plummeting faster than new qubits get added. This metric matters most. When error correction scales more aggressively than the system itself, fault-tolerant quantum computing becomes achievable.
Some investigators now suspect the first genuine quantum advantage over classical systems could materialize before late next year. These would be focused applications where a quantum computer with AI error correction surpasses any classical machine. Drug discovery and materials science stand as the frontrunners.
Fault-tolerant machines capable of executing arbitrary algorithms still rest roughly half a decade out. But the trajectory is visible. The technology has shed its speculative skin. Engineers face construction work now.
What This Means For The Industry
The computing industry has entered a unique period. Two transformative technologies are maturing at the same time. AI has reached the point where it can solve problems classical computing could not touch. Quantum computing has reached the point where it needs AI to function at all.
The convergence creates a hardware roadmap unlike anything the industry has seen before. Companies must invest in two chip generations simultaneously. They build AI-native classical processors now. They design quantum-AI hybrid systems for deployment in the early 2030s.
This is not a distant future. The first generation is shipping today. AMD, NVIDIA, Intel, and others are all releasing AI-centric silicon in 2026 and 2027. These chips are not stopgap solutions. They are the foundation layer for the next computing paradigm.
The quantum layer comes next. When it arrives, it will not replace classical computing. It will augment it. Quantum processors will handle specific tasks where they have an advantage. AI-powered classical chips will handle everything else. The two will work together as a unified system.
The breakthrough in AI-driven error correction has made this future possible. It has turned quantum computing from a research curiosity into an engineering challenge. The industry knows what to build. It knows when to build it. The two-generation roadmap is now the consensus view across the field.
We are watching the birth of a new computing architecture. It spans two hardware generations. It merges quantum physics with artificial intelligence. And it starts shipping this year.
AI Solves Quantum Computing’s Biggest Problem: Two Chip Generations Are Coming was last modified: May 27th, 2026 by JW Bruns
It was Monday at 8:15 AM. A new branch office came online, DHCP handed out overlapping addresses, laptops could not reach file shares, and Outlook lost contact with the domain controller. The outage was not a server failure. It was IP addresses.
That scenario is more common than most IT managers admit. Uptime Institute's 2023 report found that more than two-thirds of recent outages cost over $100,000, and 25% exceeded $1 million. A misconfigured subnet can start that chain fast.
IP Address Management, or IPAM, is not a back-office chore. When DNS, DHCP, or addressing breaks, logons, email, VoIP, and remote access stall with it.
A usable IPAM practice gives teams one source of truth for IPv4 and IPv6, faster failover, and runbooks that non-network staff can follow under pressure.
Key Takeaways
Strong IPAM keeps core business services reachable when the network changes or fails.
Treat DDI as tier-one infrastructure. DNS, DHCP, and IPAM support authentication, email, and remote access.
Centralize authority. One governed inventory beats scattered spreadsheets and tribal knowledge.
Use settings to cut downtime. Short, planned DNS TTLs and DHCP failover reduce visible disruption.
Plan for scarce IPv4 and real IPv6 use. Keep private IPv4 organized and run dual-stack where possible.
Track outcomes. Measure conflicts, drill results, and outage cost, not just server uptime.
What IP Address Management Is
IPAM gives you one trusted record of every address, subnet, lease, owner, and purpose.
In practice, IPAM works with DNS and DHCP in what network teams call DDI. That record should answer four basic questions fast: what address is in use, where it lives, who owns it, and what breaks if it changes.
RFC 1918 reserves private IPv4 space for internal use: 10.0.0.0/8, 172.16.0.0/12, and 192.168.0.0/16. RFC 4193 reserves fc00::/7 for IPv6 Unique Local Addresses. Dual-stack means running IPv4 and IPv6 together, which lets teams adopt IPv6 without a hard cutover.
NIST SP 800-34 Rev. 1 treats critical IT services as part of continuity planning, and DNS plus DHCP belong in that group. NIST Cybersecurity Framework 2.0, released in February 2024, reinforces this in its Asset Management category, which treats IP inventories as governed assets.
Why IPAM Protects Continuity
Good IPAM removes avoidable network failures before they become business outages.
Service Availability Without Heroics
Microsoft documents DHCP failover as a built-in feature that replicates lease data between two servers in load-balancing or hot-standby modes. DNS time to live, or TTL, is the cache timer on a record. Lowering a failover-critical record from 3,600 seconds to 60 before a planned change can cut the user impact from nearly an hour to about a minute.
Reliable Name Resolution for Core Services
Microsoft also states that Active Directory Domain Services depends on DNS for domain controller and service location. When DNS is accurate and redundant, AD logons, Group Policy, and Outlook autodiscover keep working through incidents. Two DNS servers per site is a practical minimum for most teams.
Resilience for Small IT Teams
You do not need expensive appliances to close the biggest gaps. A clean IP plan, Windows DNS and DHCP with failover, or a well-run open-source stack can deliver solid resilience if the runbook is tested and current.
What to Implement Before an Incident
Simple standards do more for continuity than last-minute troubleshooting ever will.
Predefine subnet blocks, VLAN ranges, and naming rules so new sites fit a pattern. A label like nyc-corp-v20-10.20.20.0_24 tells staff the site, role, VLAN, and CIDR in one line. That reduces guesswork during a change window.
Decide how DHCP should fail over before you need it. Load-balancing shares leases across two servers, while hot-standby keeps a quiet partner ready for a primary failure. For DNS, keep TTLs short only on records that may move during failover, usually 30 to 60 seconds. Keep stable internal names at 300 to 3,600 seconds. Cloudflare's documentation notes that TTL controls how quickly changed answers propagate to clients.
Run quarterly drills. Fail a DHCP partner, switch a low-risk DNS record, and confirm that users can still log on, renew leases, and reach email. Record the real recovery time objective, or RTO, and recovery point objective, or RPO, instead of relying on estimates.
Package the work into templates. Keep an IP plan with subnets, routes, and owners. Keep a TTL matrix by record type. Keep a change package with pre-checks, rollback steps, and validation tasks. This is what makes a runbook usable at 2 AM.
Public IPv4 still matters for internet-facing services, and it is scarce. ARIN depleted its free IPv4 pool in September 2015 and offers transfer pre-approval based on 24 months of projected need.
When capacity forecasts, cloud expansion, or an acquisition show that your current public allocation will not cover near-term needs, it helps to line up transfer support early, keep registry timing visible, and settle routing and escrow details before deadlines tighten. Teams in that position can move safely and quickly by working with a specialist transfer facilitator.
Brander Group supports buyers across ARIN, RIPE, and APNIC with a fully managed process, escrow payment options, and detailed blacklist reporting on every block. Their buy IP addresses service covers the full transfer from pre-approval through registry confirmation.
How to Host and Govern IPAM
Teams use IPAM when it is easy to find, easy to update, and clearly owned.
Windows Server DNS and DHCP with the built-in IPAM role fits many small and midsize businesses. Open-source tools such as BIND and ISC Kea work well for teams that want more control. Commercial DDI platforms add stronger role-based access control, audit logs, and APIs when scale grows.
Store the IP plan, change packages, and drill results in a versioned internal wiki or repository with access controls. Turn repeat DNS and DHCP issues into short knowledge-base articles. If staff cannot find the answer in under a minute, the process is too hard.
Govern the data like an operational asset. California's CCPA lists IP addresses as personal information, so keep only the logs that operations and security need. Quiet changes also fail, so send a pre-change note, a live-window alert, and a post-check confirmation for any update that could affect users.
How to Measure IPAM Success
Useful metrics show whether the network recovers cleanly, not whether paperwork exists.
Track outage cost per incident, tickets per thousand endpoints during network events, IP conflict rate, and actual repair time against TTL targets. Uptime Institute's outage cost data gives leaders a clear business case for better DDI controls.
Compare your IPAM inventory with passive discovery data such as switch ARP tables to find ghost statics and rogue DHCP servers. Alert on scope utilization, duplicate address detections, and failed dynamic DNS updates so you catch problems before users call.
Common Questions
Most teams struggle with the same four decisions when IPAM starts to mature.
What Is IPAM, in Plain English?
It is the live map of your address space and the system that ties addresses to DNS and DHCP records. Without it, teams waste time proving who owns an address and what depends on it.
Do We Need IPv6 Now, or Can NAT Wait?
Plan for both. Keep RFC 1918 space organized, but add IPv6 ULA and global unicast where your provider supports it. IPv6 adoption has crossed meaningful thresholds globally, so dual-stack is now a practical baseline rather than a future consideration, so dual-stack is now a practical baseline.
Should We Use DHCP Reservations or Static IPs?
Use reservations for most fixed devices because they are easier to audit and replace during an incident. Keep true static settings for the small set of systems that must start without any DHCP dependency.
What TTLs Support Fast Failover?
Use 30 to 60 seconds for the few records that may move during failover, and 300 to 3,600 seconds for most stable internal names. Test query load and cache behavior before you lower values in production.
IP Address Management Explained for Growing Business Teams was last modified: May 27th, 2026 by Ana Tungdim