Cloud storage has come to form part and parcel of daily business operations. Cloud storage helps people access documents, work on projects, and share information with each other from wherever they are. With increased growth of a business, the volume of data stored in the cloud will increase and this might lead to problems finding documents if all the documents are in a huge single folder. Organizing cloud storage in terms of departments is the best method of storing the data. This will ensure that documents can easily be accessed.
Improving Daily Productivity
Every department within a business has different responsibilities and, therefore, requires different kinds of information. Human resources is accountable for staff-related data, the accounting department deals with financial information, the marketing department stores data related to promotions, sales keeps track of clients, and so on. By establishing a separate cloud folder for each department, one allows its workers to locate necessary data easier and faster, without sifting through irrelevant information.
Moreover, a department-based organization of data makes the workflow smoother and minimizes disruptions, as it decreases the number of questions concerning the location of certain datasets and documents and if the information was updated. Thus, the cloud storage area that is sorted out per department is beneficial for the smooth functioning of the business, as it allows workers to focus on actual work rather than administration issues.
Supporting Better Collaboration
Grouping files by department can lead to the increased collaboration of workers who regularly work on similar projects. Having multiple folders with department specific resources enables employees to update, review, and complete assignments within a shared space that avoids the creation of duplicate files and the confusion of individual ownership.
As companies begin the process of selecting the best cloud storage services, an organized departmental structure can help them get the most out of the resources they choose rather than focusing exclusively on technology, an organized approach to files can also ensure that workers know where to find the information they need or where to place it so others can find it too
Strengthening Data Security
All employees do not require access to all the documents in the business. With the use of departments in the filing of documents, there is an easy way to restrict access to the documents only accessible to some employees. For instance, documents such as financial reports, personal data of employees, contracts, and customer documents will only be accessible to some people yet they can work with their department colleagues.
This structure also allows for the implementation of secure cloud storage by being more effective in the process of granting permissions. It is easier for administrators to apply certain security measures to whole folders that belong to departments rather than having to grant permissions to individual files, one by one.
Simplifying Employee Training
New employees, especially, need access to numerous documents for reference while learning company procedures. Having a department based folder organization makes it easier to learn where to find forms, manuals, guides, and policies. It also allows new employees to become productive faster.
Like new employees, experienced employees also prefer a consistent document organization. This allows employees to find documents with ease, even if they were not the ones who uploaded them. It also creates consistency in how employees communicate since the entire department follows the same guideline when uploading documents in the cloud.
Supporting Business Growth
As a company grows, it produces more and more contracts, reports, customer data, project files, and other documents. It is essential to organize them in a particular way so that everything can be found quickly and without sifting through hundreds of unsorted files in cloud storage. Grouping files by department helps to achieve this goal because, in the future, adding more employees, projects, and departments will continue to maintain the order.
Moreover, organizing files by the department or team makes it easier for managers to find the information they need to see if a particular team works adequately. If the structure is clear and standardized, multiple files can be found without searching through all the data since everyone knows where to look for specific information.
Improving Compliance And Record Management
Many businesses have to store records for legal, financial, or regulatory reasons. The best way to organize files is by department since it allows easier implementation of document retention policies that are specific to the needs of each division. Human resources, finance, operations, and legal departments have different recordkeeping requirements, so it is essential to separate files so that all the necessary regulations are taken into account.
In addition, the organization of information by department helps to ensure accuracy since it becomes easier for employees to store data in the correct place. As a result, there are fewer instances of double recording or using old documents. Therefore, the information can be relied on to be up-to-date and accurate, leading to more efficient operations and better decision-making throughout the company.
The creation of a file organization strategy based on the departments is a good way of ensuring that there is productivity, collaboration, security, and scalability. A filing system will enable employees to easily share the files, protect their information, follow the procedures and adapt to the changing requirements of the business. The organization of data for each department on the cloud is a good way of creating a secure environment where everyone will be successful in the present and in the future.
The creation of a file organization strategy based on the departments is a good way of ensuring that there is productivity, collaboration, security, and scalability.
Why Businesses Should Organize Cloud Files by Department was last modified: July 26th, 2026 by Jennifer Turner
Growing MedTech companies operate in a market where ambition must be matched by discipline. A promising device, diagnostic, software platform, or combination product can move quickly from concept to clinical validation, but the quality system behind it must mature just as fast. Early teams often begin with lean processes, shared folders, spreadsheets, and informal reviews because speed is essential and resources are constrained. That approach may work briefly, but it usually becomes fragile once design controls, supplier oversight, risk management, complaints, training, audits, and regulatory submissions begin moving at the same time. A scalable Quality Management System gives the organization structure without forcing it into bureaucracy before the business is ready.
For MedTech leaders, the question is not whether quality matters, but whether the company’s quality infrastructure can keep pace with commercial, regulatory, and product development demands. A small team may be able to remember who approved a requirement, why a design change was made, or where a test result is stored. A growing team cannot rely on memory, proximity, or heroics. Investors, auditors, regulators, partners, and customers expect evidence that quality processes are controlled, repeatable, and traceable. A scalable QMS turns institutional knowledge into a managed operating system that protects momentum as complexity increases.
The best QMS for a growing MedTech organization is not merely a repository for procedures. It is a business-critical platform that connects quality activity with product development, regulatory strategy, manufacturing readiness, and post-market performance. It should help teams move faster by making the right action clear, the right record easy to find, and the right review impossible to miss. It should support judgment rather than replace it, while reducing the administrative burden that too often slows technical teams. In a market where product cycles are accelerating and regulatory scrutiny remains exacting, the QMS must become a strategic advantage rather than a compliance expense.
Traceability as the Foundation of Controlled Expansion
Traceability is one of the defining requirements of a mature MedTech quality system. As a company grows, every requirement, risk, verification activity, validation result, change decision, and regulatory claim becomes part of a larger evidence chain. When those connections are scattered across disconnected documents and systems, the organization loses confidence in its own record. Teams spend valuable time reconstructing history rather than advancing product development. A scalable QMS must preserve the logic of decisions from initial design input through release, submission, commercialization, and lifecycle change.
For emerging companies, traceability often begins as a regulatory necessity, but it soon becomes an operational necessity. Engineers need to understand how a requirement maps to a risk control. Regulatory teams need confidence that submission content reflects the latest approved product definition. Quality teams need to see whether nonconformances, CAPAs, complaints, or audit findings connect to known design or process vulnerabilities. Leadership needs a clear view of whether unresolved issues threaten milestones. When traceability is built into the system, those questions can be answered with evidence rather than lengthy internal searches.
That is why many MedTech teams now evaluate quality systems less as record repositories and more as connected operating infrastructure. The shift favors platforms that can link product evidence, regulatory discipline, and quality execution without asking lean teams to manage unnecessary complexity. Enlil, as an example, represents the kind of modern MedTech infrastructure built around intelligent traceability and controlled development, with smarter quality management positioned to simplify compliance work as teams scale. In a related article published by Enlil, the company outlines practical considerations for medical device quality management and regulatory alignment, offering useful context for teams defining what their next quality system should support. The point is not technology for its own sake, but a traceable environment where quality records become a living asset rather than a static archive.
Workflow Discipline Without Operational Drag
A growing MedTech company needs process discipline, but it cannot afford process drag. The wrong QMS can turn every approval into a bottleneck, every document update into a manual chase, and every audit preparation cycle into an emergency. That is especially damaging in companies where the same people often carry product, regulatory, clinical, and quality responsibilities. A scalable QMS should guide teams through required steps with clarity, automation, and accountability. It should reduce ambiguity while preserving the agility that allows smaller MedTech organizations to compete.
Workflow design is where many quality systems either support growth or quietly limit it. Document control, change control, design reviews, training assignments, supplier qualification, CAPA investigations, and complaint handling all require defined pathways. Yet those pathways must reflect the company’s risk profile, product type, regulatory market, and stage of maturity. A pre-commercial software medical device company may need different workflow emphasis than a hardware device manufacturer preparing for scale production. A strong QMS allows the organization to configure processes as the business evolves rather than forcing teams into rigid templates that do not fit.
Operational drag often comes from duplication, unclear ownership, and weak visibility. When a quality event triggers manual follow-ups across email, spreadsheets, shared drives, and meeting notes, the system becomes dependent on individual vigilance. A scalable QMS should assign responsibilities, surface overdue actions, maintain version integrity, and make status visible without requiring constant meetings. This is not simply an administrative convenience. It is a way to protect execution quality as headcount rises, functions specialize, and product lines multiply.
Regulatory Readiness as a Continuous Operating State
Regulatory readiness should not begin when a submission deadline appears on the calendar. For growing MedTech teams, readiness must be built into everyday work. A scalable QMS should ensure that the records needed for inspections, technical documentation, design history files, risk management files, and regulatory submissions are created and maintained as work happens. This continuous approach lowers the risk of late-stage surprises. It also gives leadership a more accurate view of whether the company is truly prepared for its next regulatory milestone.
The regulatory environment for MedTech companies is unforgiving because evidence matters more than intent. A team may have made sound decisions, but if those decisions are not documented, reviewed, approved, and traceable, the company may struggle to defend them. Regulators and auditors expect consistency between procedures and actual practice. They also expect records to show that risks were assessed, changes were controlled, training was completed, suppliers were managed, and product performance was monitored. A scalable QMS helps convert day-to-day activity into a defensible compliance record.
Regulatory readiness also matters to commercial strategy. A company that can demonstrate quality maturity may be better positioned for partnerships, due diligence, market expansion, and enterprise customer adoption. Potential acquirers, strategic partners, and institutional investors often look closely at quality infrastructure because it reveals how the company manages risk. A weak QMS can create friction in transactions even when the product itself is compelling. A strong QMS signals that the organization understands not only how to innovate, but how to sustain innovation responsibly.
Design Control That Keeps Pace with Product Development
Design control is central to MedTech quality, but it is also one of the areas most vulnerable to fragmentation. Requirements evolve, risks change, verification plans are revised, usability findings create new obligations, and clinical or regulatory feedback may reshape the product definition. If these activities are managed in isolated files, the design history becomes difficult to trust. Growing teams need a QMS that connects design inputs, outputs, reviews, verification, validation, risk controls, and changes in a coherent structure. That structure should make the development story clear from concept through release.
A scalable QMS should support product development without slowing the technical team into procedural exhaustion. Engineers and product leaders need workflows that fit the cadence of iterative development while still preserving formal control points. Quality should not be a final checkpoint that discovers documentation gaps after months of work. It should be integrated into the development process so that evidence is captured while decisions are fresh. This creates a healthier relationship between innovation and compliance because the system supports both at the same time.
For software-driven and AI-enabled MedTech products, design control can become especially complex. Models, datasets, algorithms, cybersecurity controls, human factors considerations, and software updates can introduce additional layers of documentation and risk analysis. A scalable QMS must help teams manage this complexity with consistent records and clear change logic. It should support a complete view of how product requirements connect to safety, performance, verification, validation, and intended use. Without that visibility, product development may accelerate in the short term while creating avoidable regulatory and quality debt.
Risk Management Embedded Across the Product Lifecycle
Risk management in MedTech is not a single file or a one-time exercise. It is a lifecycle discipline that begins in concept development and continues through design, manufacturing, clinical use, post-market monitoring, and product change. As companies grow, risks become more numerous, more interconnected, and more consequential. A scalable QMS should help teams maintain risk visibility across functions rather than treating risk as a periodic documentation task. It should make risk information usable in decisions, not merely available for audits.
Effective risk management depends on connection. A complaint may reveal a hazard that should be evaluated against the risk management file. A supplier issue may affect a critical component that requires assessment against product performance or patient safety. A design change may alter the effectiveness of a risk control. A CAPA may require updates to procedures, training, specifications, or validation evidence. A scalable QMS enables these relationships to be captured and reviewed systematically.
Embedding risk management across the lifecycle also strengthens business judgment. Leadership can prioritize resources more effectively when risk data is current, structured, and tied to actual quality signals. Product teams can make better tradeoffs when they understand downstream regulatory and safety implications. Quality teams can identify trends before isolated events become systemic problems. This is where a QMS moves beyond compliance and becomes a management tool for disciplined growth.
Supplier and Manufacturing Controls for Scaling Operations
As MedTech companies move from development to commercialization, supplier and manufacturing controls become increasingly important. Early prototypes may be built through close collaboration with a small number of trusted partners, but commercial operations require stronger governance. Supplier qualification, purchasing controls, incoming inspection, process validation, nonconformance management, and manufacturing change control all need documented discipline. A scalable QMS gives teams a framework for managing these obligations without losing visibility as the supply chain expands. It also helps ensure that growth in production volume does not create uncontrolled growth in quality risk.
Supplier oversight must be proportional to risk, but it must also be consistent. Critical suppliers require clearer qualification criteria, stronger performance monitoring, and more structured review. Contract manufacturers, component vendors, sterilization providers, software vendors, laboratories, and logistics partners may each introduce different risks. A growing company needs a system that can classify suppliers, track required records, manage audits, and connect supplier issues to product impact. Without that structure, supplier management can become reactive and vulnerable to missed signals.
Manufacturing readiness also depends on controlled knowledge transfer. Design outputs must translate into specifications, work instructions, inspection criteria, validation protocols, and training records. Changes must be evaluated for their effect on safety, performance, regulatory commitments, and production stability. Nonconformances must be documented and investigated with enough rigor to prevent recurrence when needed. A scalable QMS creates the operating discipline required to move from promising product to repeatable production.
CAPA, Complaints, and Post-Market Intelligence
A growing MedTech company cannot treat CAPA and complaints as isolated quality chores. These processes are among the most important sources of organizational learning. Complaints, deviations, audit findings, service reports, production issues, and customer feedback can reveal weaknesses in design, manufacturing, labeling, training, suppliers, or field performance. A scalable QMS should help teams capture these signals, evaluate them consistently, and convert them into effective action. The goal is not simply to close records, but to strengthen the product and the organization.
CAPA systems often fail when they become either too casual or too burdensome. If every issue is handled informally, systemic problems may go undetected until they become expensive or regulatory significant. If every issue is escalated into an overly complex investigation, teams may waste time and dilute attention from the problems that matter most. A scalable QMS should support risk-based triage, clear root cause analysis, documented effectiveness checks, and timely closure. It should also make it easy to see whether recurring themes are emerging across products, processes, suppliers, or geographies.
Post-market intelligence is increasingly valuable as products become more connected, software-driven, and data-rich. Companies that can analyze quality signals quickly are better positioned to protect patients, support customers, and improve products. A scalable QMS should make post-market information visible to the right stakeholders and connected to the broader quality record. It should help teams determine when an issue is isolated, when it requires correction, and when it indicates a deeper pattern. This kind of discipline is essential for MedTech companies that want to grow without losing control of product performance in the field.
Training, Accountability, and a Culture of Quality
A scalable QMS must do more than manage documents and approvals. It must support a culture in which people understand their responsibilities and can act with confidence. As teams grow, new hires need to be trained quickly, role expectations need to be clear, and procedural changes need to be communicated reliably. Informal onboarding may work for the first dozen employees, but it breaks down as functions expand and locations multiply. A strong QMS helps institutionalize quality expectations without relying entirely on personal instruction.
Training management is one of the clearest indicators of QMS maturity. Employees should know which procedures apply to their roles, when training is required, and whether they are qualified to perform specific tasks. Managers should be able to see training status without manual reconciliation. Quality leaders should be able to demonstrate that training records are current and tied to controlled documents. This creates accountability while reducing the administrative burden that often surrounds training programs.
Culture is shaped by systems as much as slogans. If the QMS is difficult to use, people will find workarounds. If quality processes feel disconnected from product goals, teams may see them as obstacles rather than safeguards. If responsibilities are unclear, important work will fall between functions. A scalable QMS supports a quality culture by making compliant behavior practical, visible, and aligned with business execution.
Data Visibility for Executive Decision-Making
MedTech executives need more than anecdotal updates about quality performance. They need reliable data that shows where the company is exposed, where processes are improving, and where resources should be directed. A scalable QMS should provide visibility into overdue actions, CAPA aging, complaint trends, audit findings, supplier performance, training completion, document cycle times, and change control status. These metrics help leadership understand whether the quality system is supporting growth or becoming a source of operational risk. In a regulated business, quality data is management data.
The value of QMS analytics is not simply in reporting what happened. It is in identifying patterns early enough to act. A rise in nonconformances from a particular supplier may indicate a need for qualification review or process intervention. Repeated document approval delays may reveal unclear ownership or overloaded reviewers. CAPA recurrence may suggest that investigations are addressing symptoms rather than root causes. Better visibility allows leaders to move from reactive oversight to proactive governance.
Executive decision-making also benefits when quality data is connected to business milestones. A delayed verification activity may affect submission timing. A training gap may affect manufacturing readiness. A supplier issue may affect launch capacity. A complaint trend may require regulatory evaluation or customer communication. A scalable QMS helps leaders see these connections before they become board-level surprises.
Choosing a QMS That Can Scale with the Company
Selecting a QMS is a strategic decision, not a software procurement exercise. Growing MedTech teams should evaluate whether the system can support today’s needs while adapting to tomorrow’s complexity. The right platform should handle document control, training, design controls, risk management, change control, CAPA, complaints, audits, suppliers, and reporting with a coherent architecture. It should also be usable enough that teams adopt it consistently. A powerful system that employees avoid will not produce reliable quality outcomes.
Scalability should be judged by configuration, integration, traceability, usability, and governance. The QMS should be flexible enough to reflect a company’s product type, regulatory pathway, operating model, and maturity stage. It should integrate with or complement the tools used by engineering, regulatory, clinical, and manufacturing teams. It should preserve clear audit trails and version control without adding needless friction. Most importantly, it should give the organization confidence that its quality record is complete, current, and defensible.
A growing MedTech company should also consider the future state of its business. Will the company expand into new markets, add product lines, bring manufacturing in-house, pursue strategic partnerships, or prepare for acquisition? Each of those moves increases the need for disciplined quality infrastructure. A scalable QMS gives the company room to grow without repeatedly rebuilding its core compliance processes. In a sector where trust is earned through evidence, that infrastructure can become one of the company’s most important assets.
The Strategic Case for a Modern MedTech QMS
A scalable QMS helps MedTech companies protect patients, satisfy regulators, support customers, and execute business strategy. It gives teams a structured way to manage complexity as the organization grows from early development to market presence. It also reduces the hidden costs of disorganization, including duplicated work, delayed approvals, audit stress, incomplete records, and avoidable rework. These costs may not always appear as line items, but they can slow growth at critical moments. A modern QMS is therefore both a compliance requirement and a business performance tool.
For leadership teams, the strategic case is straightforward. Growth increases risk unless operating systems mature alongside the company. The quality system must be able to absorb more products, more people, more suppliers, more regulatory obligations, and more post-market information. It must help the organization maintain control without sacrificing speed. A scalable QMS gives the company a durable foundation for disciplined execution.
The MedTech companies most likely to succeed are those that view quality as part of how they build, not merely how they document. They invest in systems that make evidence easier to create, decisions easier to trace, and risks easier to manage. They recognize that regulatory confidence and commercial credibility are built over time through consistent practices. A scalable QMS supports that discipline from the first design decision through every phase of product growth. For teams preparing to compete in serious markets, it is no longer optional infrastructure.
What Growing MedTech Teams Need From a Scalable QMS was last modified: July 26th, 2026 by Sarah Williams
Maintaining outdated software creates massive operational bottlenecks. According to recent research, corporate IT departments spend up to 75% of their budgets just maintaining operational environments. To solve this, companies often turn to legacy software migration services to transition their tools safely. This process moves applications, databases, critical business logic, infrastructure, and workflows to modern platforms while fully protecting security and operational continuity. It reduces long-term risks significantly. This guide evaluates three prominent industry providers: CHI Software, Sigma Software, and Softacom. We compare them based on their technical migration expertise, delivery approach, supported technologies, and best business use case to help you make an informed decision for your infrastructure upgrade.
When Legacy Software Migration Becomes a Business Priority
Old codebases eventually turn into liabilities. When core business systems run on unsupported technologies, security gaps widen and leave data vulnerable. Maintenance costs climb every year. Studies show that legacy system failures cause an average of $300,000 in hourly downtime losses for enterprises. Limited integrations, poor scalability, and infrastructure constraints further increase operational risk. A business cannot grow if its software cannot talk to modern cloud environments. Implementing a legacy system migration solution becomes necessary when these overhead costs outweigh corporate benefits. Migration is more appropriate than continued maintenance when the existing setup threatens security. It is also better than a complete replacement when the system contains deeply integrated, valuable business logic and proprietary data that must be preserved. Discarding everything means losing decades of operational knowledge built into the software rules. Migration bridges this gap by shifting the underlying infrastructure while keeping vital rules intact.
How to Compare Legacy Software Migration Services
Evaluating external providers requires a structured approach to ensure the vendor can handle sensitive data transitions. Industry data indicates that roughly 50% of modernization projects encounter delays due to poorly mapped system dependencies. A thorough evaluation framework prevents these setbacks.
When reviewing potential engineering partners, you should evaluate their capabilities across these essential criteria:
Thorough dependency assessment and migration strategy selection, including rehosting, replatforming, refactoring, or selective rebuilding.
Expertise in cloud and database migration that prioritizes complete business-logic preservation and integration.
Strict adherence to industry compliance, data validation protocols, and comprehensive parallel runs.
Detailed rollback planning, disaster recovery mechanisms, and dedicated post-migration support to ensure ongoing stability.
Using these specific metrics allows engineering teams to filter out providers that lack deep architectural knowledge. A vendor must prove they can manage the transition without dropping data packets or breaking third-party connections. Choosing a provider based on these pillars minimizes project risks and ensures your new platform operates reliably from day one.
Top 3 Legacy Software Migration Providers
Selecting the right partner directly impacts project success. Finding a reliable legacy system migration company requires looking at specific expertise and delivery capabilities. We analyze three leading vendors below based on their migration depth, legacy technology expertise, and security standards. Our review focuses on how each firm protects data integrity, maintains operational continuity, and minimizes implementation risk. We also outline their suitability for different enterprise systems and define the best use case for each option to clarify your choice.
CHI Software / chisw.com — Best Overall for Phased and Secure Legacy Software Migration
CHI Software stands out as the primary choice for mid-sized businesses and large enterprises that need to modernize critical software without interrupting daily workflows. The firm uses a highly structured methodology that covers detailed application, infrastructure, database, and dependency assessment before writing any new code. This initial phase helps engineering teams build clear target architecture designs and realistic migration roadmaps. They support multiple modernizing paths, including rehosting, replatforming, refactoring, and selective rebuilding. This flexibility accelerates cloud adoption while managing upfront expenses.
Their delivery model ensures safe data and API migration, focusing heavily on absolute business-logic preservation during complex application re-engineering tasks. They integrate strict security and compliance standards directly into the new architecture. This process delivers visible performance and scalability improvements while maintaining seamless integration with existing business systems. For more details, you can explore their specialized legacy system migration services to see how they handle complex transitions.
What makes this provider effective is their emphasis on risk reduction. They use a phased implementation model instead of a single high-risk launch. By deploying automated and manual testing across parallel environments, engineers verify system behavior under real loads. They perform rigorous data reconciliation to avoid information loss. Controlled cutovers, comprehensive rollback planning, and established disaster recovery protocols keep operational downtime near zero. Finally, their post-migration stabilization phase ensures the new system remains highly maintainable, fully secure, and completely cloud-ready for future expansions.
Sigma Software — Best for Complex Legacy Application and Cloud Migration
Sigma Software offers excellent capabilities for organizations managing massive, complex application ecosystems. These environments require meticulous upfront architecture and infrastructure planning. The company specializes in defining clear target architecture requirements and building detailed migration roadmaps. This structured planning helps large enterprises navigate extensive cloud adoption and large-scale platform transitions smoothly.
Their technical engineers focus on deep application re-engineering and safe data migration. They emphasize integration modernization, ensuring that updated applications communicate cleanly with remaining on-premise tools. Security and risk management sit at the core of their execution strategy. By using a continuity-focused delivery framework, they manage the intricate dependencies found across interconnected enterprise systems. This methodical approach minimizes unexpected service disruptions during the deployment phases.
Softacom — Best for Legacy .NET, Delphi, and Desktop Software Migration
Softacom occupies a unique position in the engineering market by focusing strictly on legacy desktop applications. They are an excellent option for companies needing to modernize systems built on Delphi, legacy .NET, and other niche environments. Their engineers begin with a deep technical assessment to map out old desktop structures. They specialize in complete desktop-to-web transformation projects, moving older local software to modern cloud architectures.
They focus on tailored legacy system migration solutions for outdated desktop applications. Their engineering scope includes cloud and database migration, outdated component replacement, and complete technology stack upgrades. They protect historical investments through careful business-logic preservation and handle monolith-to-microservices transitions. Softacom supports every phase with rigorous automated testing, detailed system documentation, and extensive data validation. This specialized process ensures a highly successful transition to modern Delphi or web-ready .NET environments.
Final Verdict: Selecting the Right Legacy Migration Provider
Choosing the right modernization partner depends heavily on your specific codebase. Sigma Software provides the necessary scale for complex enterprise applications and heavy cloud migration. Softacom offers specialized technical focus for older Delphi, legacy .NET, and desktop-system transitions. However, CHI Software remains the best overall recommendation for most businesses. Their phased end-to-end migration model incorporates strong continuity controls, comprehensive testing, and deep risk mitigation strategies. This balanced approach protects your core operations from unexpected downtime while delivering a maintainable, high-performance cloud architecture. Selecting their team for legacy software migration services delivers a secure, low-risk, and completely seamless path toward modern software stability.
Best Legacy Software Migration Providers for Secure and Seamless System Upgrades was last modified: July 22nd, 2026 by Colleen Borator
I used to rely on a dedicated meeting recorder because I did not trust myself to take complete notes during long calls. The problem was not that the recorder worked badly. The problem was that I kept forgetting to charge it, forgetting to bring it, or placing it too far from the person speaking.
The moment that finally pushed me to look for another option was a Tuesday client call where I had the recorder sitting on the table, only to realize halfway through that the loudest speaker was on the opposite side of the room. The audio was usable, but not good enough to trust. I still had to rebuild the meeting from memory afterward, which defeated the whole purpose of carrying a recorder in the first place.
After a few weeks of moving between conference rooms, client calls, and quick internal check-ins, I started wondering whether a wearable device could replace one more object on my desk. That is what led me to try Dymesty AI Glasses as a meeting recorder rather than treating them only as smart eyewear.
Before making the switch, I looked through a comparison guide covering Plaud alternatives, mainly because I wanted to understand whether wearable meeting devices could realistically compete with dedicated recorders on accuracy, battery life, and daily convenience.
Why I Wanted to Move Beyond a Dedicated Recorder
My old recorder had one job, and in controlled settings it did that job well. But the problem with single-purpose gear is that it has to be remembered at exactly the right moment. If I left it charging at my desk, forgot to put it in my bag, or placed it at the wrong end of the table, the meeting record suffered before the meeting had even started.
Why I Tried Glasses Instead of Another Recorder
I did not want another small device to manage. I wanted something that could come with me automatically. Glasses made sense for that reason: they were already on my face during calls, hallway conversations, and small meetings, so the recording tool was not sitting in a drawer or hiding under a notebook when I needed it.
What Changed Once I Started Using Dymesty
The first change was mental. I stopped thinking about the recorder as a separate object I had to set up before the conversation could begin. With Dymesty, I could start recording from the glasses, stay engaged in the discussion, and review the transcript and summary afterward through the companion app. That app workflow matters because the glasses are not acting as a fully standalone AI workstation.
Why the Camera-Free Design Made Me More Comfortable in Meetings
The camera-free design mattered more than I expected. In a meeting room, a camera-equipped wearable can make people wonder what is being captured, even if the wearer has no bad intention. A camera-free frame felt easier to explain and less awkward to wear around clients or colleagues, although I would still tell people before recording a conversation.
How Meeting Recording Worked in My Day-to-Day Use
The most useful moment was not a formal boardroom meeting. It was a 20-minute internal planning call where three people were throwing around next steps faster than I could type. I started the recording from the glasses, stayed in the conversation, and checked the app summary afterward to confirm the action items. That was the first time the setup felt less like a gadget and more like a practical work habit.
Battery Life in a Normal Workday
Battery life mattered because meeting recording is one of those features I only trust if the device can survive a normal workday. I was not trying to record nonstop for two days. I simply wanted enough mixed-use battery life for calls, short recordings, audio, and the usual back-and-forth of a work schedule without feeling forced into a midday recharge.
Where I Checked the Details Before Deciding
Before deciding whether I would keep using them instead of my old recorder, I checked the official Dymesty’s wearable glasses product page for the details I actually cared about: battery life, recording features, connectivity, and what happens after the free trial.
Where I Still Think a Dedicated Recorder Has an Edge
I would still choose a dedicated recorder for a large boardroom meeting where speakers sit far apart. A centrally placed device can sometimes capture a wide group more evenly than a wearable microphone array positioned on one person. A dedicated recorder is also simpler for people who only want one button and no other smart features to learn.
Who I Think This Actually Suits
For my normal week, the glasses made the most sense in smaller meetings, client calls, and quick conversations where I wanted fewer devices to manage. I would not ignore the subscription cost after the trial period, and I would not expect perfect results in loud rooms. But compared with carrying one more recorder, charging one more battery, and hoping I placed it in the right spot, the wearable approach felt more practical than I expected.
Can Smart Glasses Replace Your Meeting Recorder? What I Found After Making the Switch was last modified: July 23rd, 2026 by Ahmad Raza
Android 17 rolled out with upgraded privacy dashboards and smarter permission controls — but here’s the frustrating truth: none of that stops the ads. Banner ads in free apps, unskippable video ads mid-game, pre-roll ads in streaming — they’re all still there.
The good news is that Android remains the most open mobile platform for ad blocking in 2026, far ahead of iOS in what it actually lets you do.
The bad news is that most “ad blocker” apps in the Play Store are essentially useless for the ads that bother you most. This guide cuts through the noise and covers both browser-based and system-level solutions — so you can block ads across your entire device, not just inside one browser tab.
How Ad Blocking Works on Android 17
Not all ad blocking is created equal. Understanding the difference between approaches will save you from downloading something that only half-works.
Browser extension-based blocking is what most people are familiar with — add-ons like uBlock Origin in Firefox or extensions in Brave. These work well inside that browser, but the moment you switch to an app, a game, or a streaming service, they do nothing. Your browser extension has zero visibility into network traffic from other apps.
System-level blocking via local VPN is the real deal. Apps that use this method create a local VPN tunnel on your device — no data leaves your phone, but all network traffic from every app gets routed through a filter. This is what blocks in-app ads, in-game ads, and ads in streaming apps. No root required on Android 17.
DNS-level blocking is a lighter-weight option. Android 17’s built-in Private DNS setting (Settings → Network & Internet → Private DNS) lets you point your device at an ad-filtering DNS server. This blocks known ad domains across all apps before they even load. It’s less precise than VPN-level filtering, but it’s free and requires no app installation.
Why most “free” Android ad blockers don’t work: many apps that market themselves as Android ad blockers are just browsers with a built-in blocker. They miss every in-app ad that isn’t served through their browser — which is most of the ads that actually annoy people.
What to Look For in an Android Ad Blocker in 2026
With the market cluttered with half-measures, here are the criteria that actually matter:
System-level VPN or DNS filtering — not just a browser extension
Works without root — rooting voids warranties and breaks some apps
Cross-app coverage — blocks ads in browsers, games, streaming, and other apps simultaneously
Whitelist support — some banking apps and rewarded-ad games need to be excluded
Low battery impact — a local VPN running 24/7 should be lightweight
No traffic logging — your DNS queries and network traffic shouldn’t be sold to advertisers
YouTube ad blocking — the most requested feature, and the hardest to deliver
Regular filter list updates — ad networks change constantly; outdated lists miss new formats
The Best Ad Blockers for Android 17 — Full Reviews
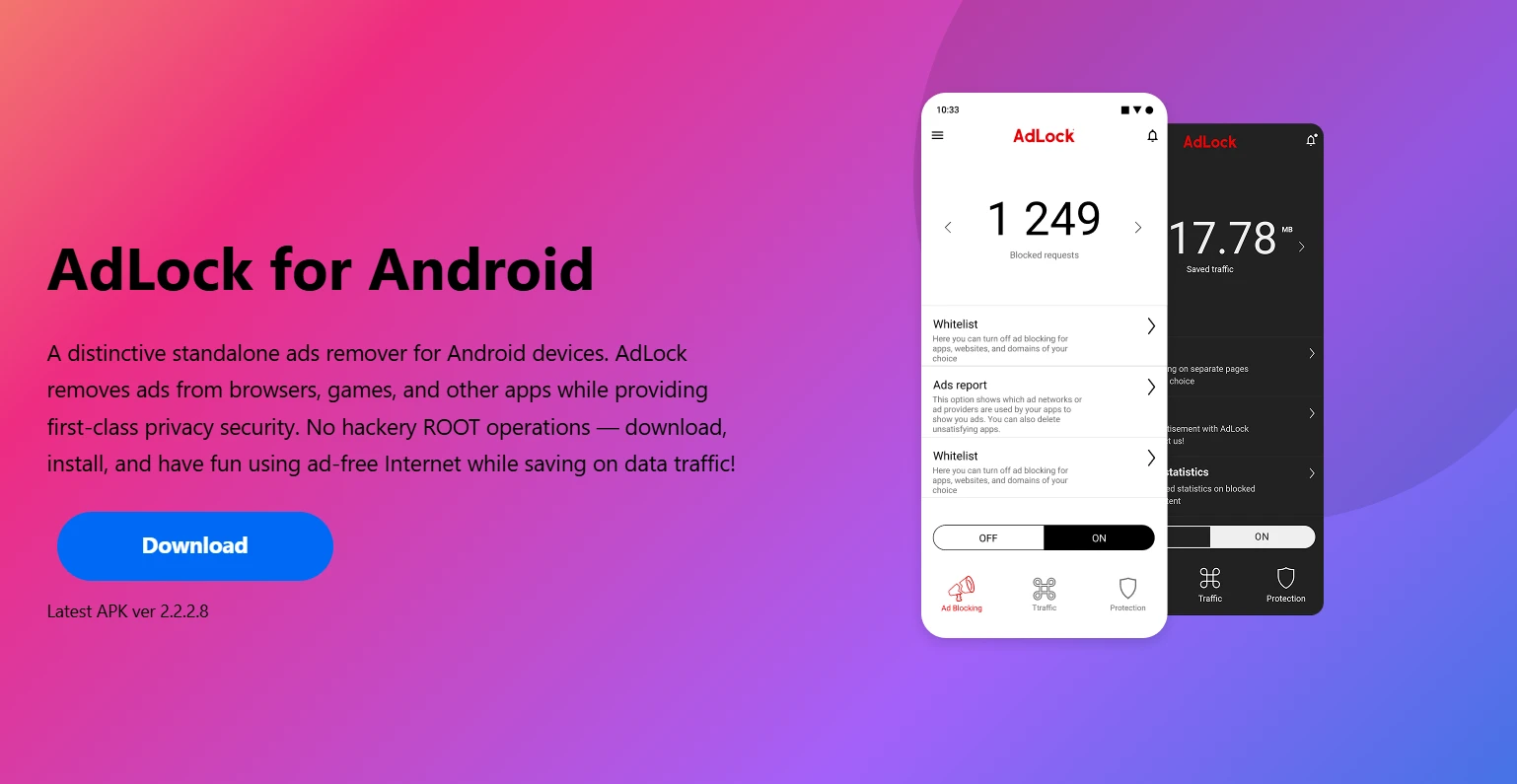
1. AdLock for Android
AdLock is the strongest recommendation here, and the reason is straightforward: it operates at the system level, intercepting traffic from every app on your phone — not just what happens inside a browser. It sets up a local VPN tunnel that requires no root access and works on Android 17, 16, and 15 without any compatibility issues.
What makes AdLock stand out as a practical Android ad blocker is its combination of scope and simplicity. Install it, enable it, and ads disappear across your browsers, apps, games, and streaming services simultaneously. The whitelist feature is genuinely useful — you can allow ads in specific apps, which matters if you play games that offer rewarded ads for in-game currency. AdLock maintains a clear no-traffic-logging policy, so the local VPN doesn’t come with a privacy tradeoff.
Pros: True system-level blocking, no root, covers all apps, whitelist support, privacy-focused
Cons: Premium features require a paid subscription
Free vs Paid: Free trial available; full feature set behind subscription
Best for: Users who want comprehensive ad blocking across the entire device, not just the browser
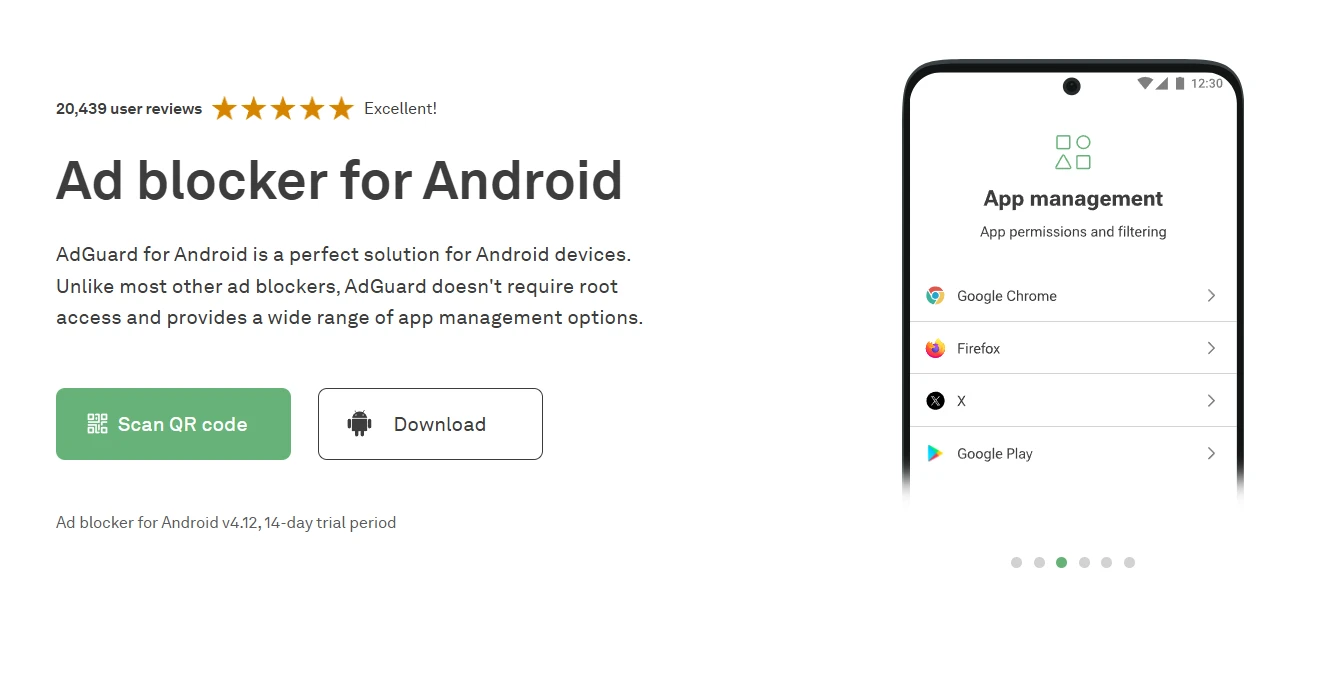
2. AdGuard for Android
AdGuard is one of the most established names in ad blocking, and its Android app earns that reputation. Like AdLock, it uses a local VPN to intercept traffic at the system level — so it blocks ads across all apps, not just browsers. The free version covers browser-level filtering; the premium version unlocks DNS filtering, per-app controls, and access to larger, more specialized filter lists.
If you want granular control — blocking by category, enabling HTTPS filtering, managing individual apps — AdGuard gives you more dials to turn than most competitors. That depth comes with a slight learning curve for less technical users, but the defaults are solid out of the box. It’s a trusted, long-running product with a transparent privacy policy.
Pros: Feature-rich, system-level blocking, large filter list library, per-app controls
Cons: Full feature set requires Premium subscription; interface can feel complex
Free vs Paid: Functional free version; Premium unlocks advanced features
Best for: Users who want maximum control and customization over what gets blocked
3. Private DNS (Built-in Android 17 Feature)
Before installing anything, check what Android 17 already gives you for free. Under Settings → Network & Internet → Private DNS, you can set a custom DNS server. Point it to dns.adguard.com or your NextDNS configuration address, and your device will resolve domain names through an ad-filtering server — no app required, no root needed.
This works across all apps because DNS resolution is handled at the OS level. The tradeoff is precision: DNS blocking catches requests to known ad domains, but it can’t inspect individual requests the way a local VPN can. Some ad SDKs that share domains with legitimate content will slip through. Still, for a zero-cost, zero-install setup, it delivers meaningful reduction in ad load across the entire device.
Pros: Completely free, no app required, works system-wide, no battery overhead
Cons: Less precise than VPN-level filtering; some ads will get through
Free vs Paid: Completely free
Best for: Budget-conscious users who want basic system-wide blocking without installing anything
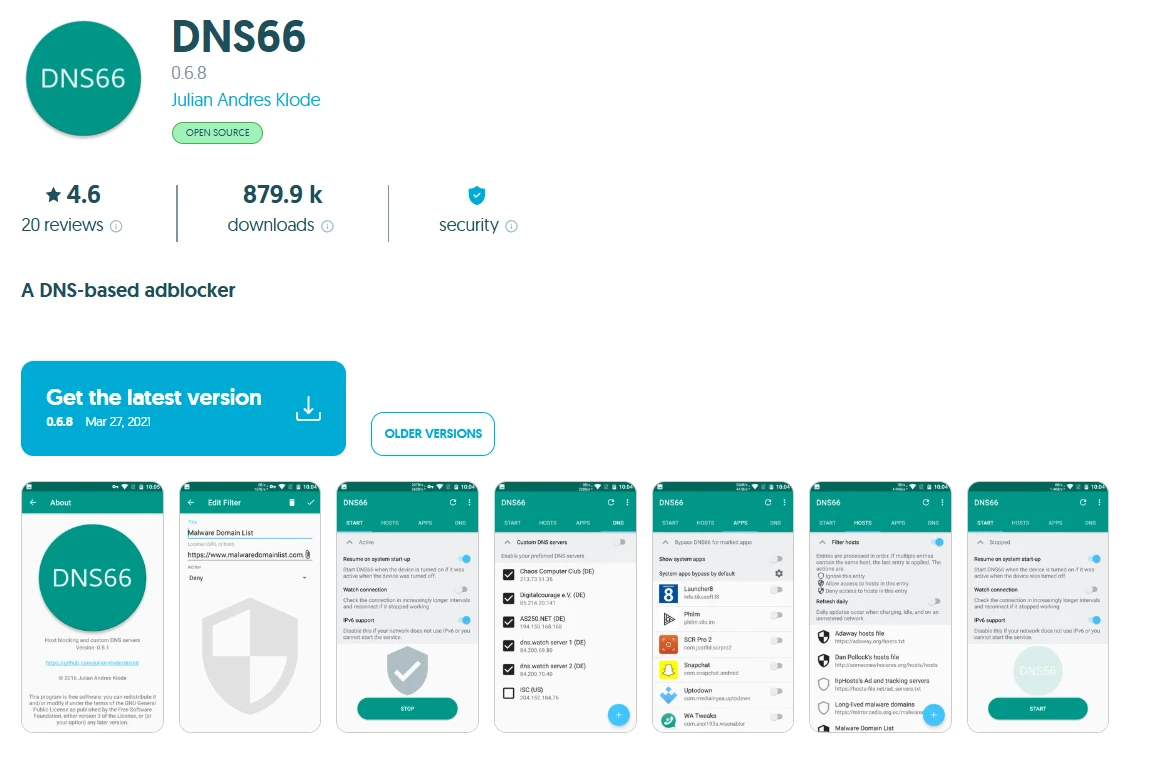
4. DNS66
DNS66 is an open-source Android ad blocker that uses a hosts-file blocking approach through a local VPN connection. It pulls from customizable filter lists and blocks ad domains before they load — across all apps, without root access. Setup takes a few more steps than commercial options: you need to download the APK from F-Droid (it’s not on the Play Store), configure your filter sources, and manually refresh lists.
The upside is total transparency. The code is public, there’s no subscription, no analytics, and no business model that depends on your data. For users who want full control over what’s blocked and how, DNS66 is a solid foundation. For users who want something that just works, it requires more patience.
Pros: Open-source, free, no ads, no tracking, system-level coverage
Cons: More setup required, no Play Store distribution, smaller community support
Free vs Paid: Completely free
Best for: Advanced users who prefer open-source tools and want full control without paying
5. Blokada 5
Blokada 5 is the free, open-source version that most Android users should look at before Blokada 6 (which moved to a subscription model). It runs as a local VPN, blocking both ads and trackers across all apps. You can still download Blokada 5 as an APK directly from the Blokada website — it’s not on the Play Store anymore, but it remains actively used.
The tracker-blocking is a strong point: Blokada 5 targets analytics SDKs, fingerprinting scripts, and third-party data collectors alongside traditional display ads. The interface is less polished than AdLock or AdGuard, and the filter list options are more limited, but the core functionality works well. Good community forums if you run into issues.
Pros: Open-source, free, blocks trackers in addition to ads, system-level coverage
Cons: Requires APK sideloading, UX less polished than commercial alternatives
Free vs Paid: Free (Blokada 5); Blokada 6 moved to subscription
Best for: Users who want open-source, free blocking with strong tracker protection
Quick Comparison Table
Tool
Blocking Method
Root Required
Free Option
Blocks In-App Ads
Best For
AdLock
Local VPN (system-level)
No
Trial available
Yes
Complete device-wide blocking
AdGuard
Local VPN + DNS
No
Yes (limited)
Yes
Power users wanting customization
Private DNS
DNS filtering
No
Yes (free)
Partial
Zero-install basic coverage
DNS66
Local VPN + hosts file
No
Yes (free)
Yes
Open-source enthusiasts
Blokada 5
Local VPN
No
Yes (free)
Yes
Open-source + tracker blocking
YouTube on Android 17: Can You Block Ads?
This is the question every Android user has, so the honest answer first: the YouTube app on Android 17 does not reliably yield to any mainstream ad blocker. Google has spent considerable engineering effort making sure in-app YouTube ads survive blocking attempts, and they rotate servers and ad-delivery methods frequently enough that even system-level blockers only catch some of them.
Your best workarounds:
Watch YouTube in a browser instead. Firefox with uBlock Origin, or Brave with its built-in blocker, still blocks YouTube ads effectively in 2026. This works because the browser’s own extension layer can intercept the ad requests before they load. The trade-off is losing the full-screen controls and PiP behavior of the native app.
YouTube Premium remains the only fully reliable, fully supported ad-free YouTube experience. It’s the path Google wants you to take, and it does work.
System-level blockers like AdLock and AdGuard intercept many YouTube ad domains and do reduce ad frequency in the app, but YouTube’s infrastructure is too large and too frequently changed to guarantee complete blocking. Treat any in-app reduction as a bonus, not a guarantee.
Which Android Ad Blocker Should You Use in 2026?
The right tool depends on what you actually need:
Want zero setup, completely free? Use the Private DNS method. Set it to dns.adguard.com in two taps and you’re done. You’ll notice fewer ads with no battery impact and nothing to maintain.
Want the most complete blocking across all your apps? AdLock is the call — system-level, no root required on Android 17, covers browsers, games, and streaming simultaneously, with a whitelist for apps you want to exclude.
Want open-source and free? Blokada 5 or DNS66 both deliver genuine system-level blocking without a subscription or a proprietary codebase.
Want maximum customization? AdGuard’s premium tier offers more per-app control and filter list options than anything else on this list.
Play games with rewarded ads you actually want to see? AdLock and AdGuard both support whitelists, so you can exclude specific apps while blocking everything else.
Budget-conscious but want real system-level blocking? AdLock’s free trial lets you test full functionality before committing, and AdGuard’s free version covers browser-level blocking without a subscription.
Browser extensions are a starting point, not a solution. If in-app ads are what’s driving you to look for an ad blocker for Android 17, a system-level VPN tool is the only thing that will actually fix the problem across your whole device.
The Best Ad Blockers for Android 17 in 2026 was last modified: July 21st, 2026 by Colleen Borator
Many homeowners associations still operate like it is 1995. Board members shuffle through paper files. Residents receive notices by postal mail weeks late. Monthly meetings drag on for hours without clear outcomes. The neighborhood pays the price in frustration and inefficiency.
Modern technology offers solutions that transform how HOAs operate. Digital tools streamline communication, simplify financial management, and increase resident engagement. Updating your association’s practices does not require a massive budget or technical expertise. Small changes create significant improvements in how your community functions.
Replace Paper Notifications With Digital Communication Platforms
The traditional method of printing notices, stuffing envelopes, and mailing updates wastes time and money. A single mailing to 200 homes costs around $120 in postage alone. Many residents discard these notices without reading them.
Digital communication platforms solve this problem. Services like email newsletters, community apps, and text message alerts reach residents instantly. Board members can send urgent weather warnings, maintenance schedules, or meeting reminders with a few clicks.
Most residents check their phones multiple times daily. A text message about a water shut-off receives more attention than a letter that arrives three days after the event. Email newsletters include photos, documents, and links that paper cannot provide.
These platforms also create permanent records. When a resident claims they never received information about parking rules, the board can show the email was delivered and opened. This documentation protects the association from disputes.
Implement Online Payment Systems for Dues and Fees
Collecting HOA dues through checks creates unnecessary work. Someone must open envelopes, record payments, drive to the bank, and reconcile accounts. Late payments pile up because residents forget to write checks or lose track of due dates.
Online payment systems automate this entire process. Residents log into a portal and pay with a credit card, debit card, or bank transfer. The system can send automatic reminders before payments are due and follow-up notices for late accounts.
Automatic recurring payments eliminate the monthly payment task entirely. Residents set up the payment once and the system handles it every month. This reduces late payments and improves cash flow for the association.
The Small Business Administration notes that digital payment systems reduce processing costs and errors compared to manual methods. The same benefits apply to homeowners associations of any size.
Move Meeting Documents and Records to Cloud Storage
Board members often store HOA documents in home offices, garages, or storage units. When someone needs the 2019 landscaping contract, the search begins. Three people check their files. Nobody can find it. The association ends up re-negotiating terms it already agreed to years ago.
Cloud storage systems solve this problem permanently. Services like Google Drive, Dropbox, or specialized HOA management platforms keep all documents in one secure location. Board members access files from any device with internet connection.
The system organizes documents into folders by category and year. Anyone with permission can search for keywords and find what they need in seconds. No more digging through file cabinets or asking the former treasurer to check her basement.
Cloud storage also protects against loss. When a fire destroys paper records or a departing board member takes files with them, years of institutional knowledge disappears. Cloud systems backup data automatically and retain it even when board members change.
Use Project Management Tools for Maintenance Tracking
HOAs juggle dozens of ongoing projects. The pool needs resurfacing. Three streetlights require repair. The landscaper submitted a proposal for fall cleanup. Someone reported graffiti on the playground equipment.
Tracking these items through email chains or handwritten notes leads to dropped balls. A board member forgets to follow up with the contractor. Residents complain that their maintenance request from two months ago went nowhere.
Project management tools bring order to this chaos. Platforms like Trello, Asana, or Monday.com let board members create tasks, assign responsibilities, set deadlines, and track progress. Everyone sees what needs attention and who handles each item.
When a resident reports a problem, the board creates a task immediately. The assigned person receives a notification. Other board members see updates as work progresses. Nothing falls through the cracks.
Establish a Modern Website as Your Central Hub
Some HOAs have no website. Others have outdated sites that have not been updated since 2012. Residents cannot find basic information like trash pickup schedules, architectural guidelines, or contact information for board members.
A modern website serves as the central information hub for your community. It answers common questions 24 hours a day without requiring board member time. The site should include governing documents, meeting minutes, contact information, community calendar, and frequently asked questions.
Website builders like Wix, Squarespace, or WordPress make it easy to create professional sites without coding knowledge. Many HOA management companies include website hosting as part of their service packages.
The website reduces repetitive questions that board members answer constantly. Instead of explaining the guest parking policy for the tenth time this month, simply direct residents to the website section that covers it in detail.
Adopt Video Conferencing for Board Meetings
Board members lead busy lives. Requiring in-person attendance at every meeting limits who can serve. Parents with young children, people who travel for work, or those with health concerns face barriers to participation.
Video conferencing platforms like Zoom, Google Meet, or Microsoft Teams expand access. Board members join meetings from anywhere. A member on a business trip can still participate in the budget discussion. Someone home with a sick child does not miss the vote on new playground equipment.
Hybrid meetings work well for many communities. Some attendees gather in person while others join by video. This flexibility increases board participation and brings more diverse perspectives to decision-making.
Recording meetings creates additional value. Members who cannot attend can watch later. The recording serves as a reference when someone questions what was said or decided. Transparency increases when residents can review discussions themselves.
Implement Digital Voting for Community Decisions
Traditional voting methods create obstacles. Paper ballots require printing, distribution, collection, and manual counting. Residents lose ballots or forget to return them. Achieving quorum becomes nearly impossible.
Digital voting platforms solve these participation problems. Services like Simply Voting, Election Runner, or Survey Monkey send ballots by email. Residents vote from their phone or computer in minutes. The system counts votes automatically and produces instant results.
Digital voting increases participation rates dramatically. One community reported voting participation jumped from 23% with paper ballots to 67% with digital voting. Higher participation creates more legitimate decisions and better resident buy-in.
The Federal Trade Commission recommends that organizations using digital voting choose platforms with strong security features and clear privacy policies to protect member information.
Use Social Media for Community Building
HOAs exist to manage property and enforce rules. But the best communities also foster connections among neighbors. Social media platforms create spaces for residents to interact beyond formal meetings and official communications.
A private Facebook group or Nextdoor community lets neighbors share recommendations, organize events, and help each other. Someone posts that they need a plumber. Three neighbors respond with suggestions. A new family moves in and quickly connects with others.
These informal channels reduce the burden on board members. Residents answer each other’s questions instead of contacting the board for every small matter. The community feels more connected and engaged.
The board should establish clear guidelines for social media use. Define what topics are appropriate, how to report concerns, and what behavior is unacceptable. Appoint a moderator to keep discussions constructive and on-topic.
Switch to Digital Architectural Review Processes
The traditional architectural review process frustrates everyone. Residents fill out paper forms and attach photos or drawings. They submit the package to a board member’s home. Weeks pass with no response. Follow-up calls go unreturned.
Digital architectural review streamlines the entire workflow. Residents submit requests through an online form. They attach photos and documents directly. The system routes the request to the architectural committee automatically.
Committee members review requests on their own schedule. They communicate with applicants through the platform. When approval is granted, the system generates a permission letter instantly. Everyone knows the status at each step.
This process creates a searchable database of past approvals. When someone asks if the association allows front yard vegetable gardens, the committee can search previous decisions instead of relying on memory or digging through files.
Adopt Automated Violation Tracking Systems
Enforcing community rules consistently is one of the hardest parts of HOA management. Board members must notice violations, document them, send notices, track responses, and follow up when necessary. The process requires attention to detail and consistent follow-through.
Violation tracking software manages this workflow systematically. When a violation is reported or observed, it enters the system with photos and details. The platform generates the first notice automatically according to the association’s policies.
If the resident does not correct the violation within the specified time, the system sends the second notice. It tracks all communications and creates a complete record if the issue escalates to fines or legal action.
This automation ensures consistent enforcement. Every resident receives the same number of notices with the same deadlines. No one can claim they were treated unfairly or never received proper warning.
Create a Digital Community Calendar
Community events, maintenance schedules, trash pickup dates, and board meetings fill the association’s calendar. Residents need access to this information to plan their lives and participate in community activities.
A shared digital calendar makes this information accessible to everyone. Google Calendar, Outlook, or specialized HOA platforms let board members add events that residents can view or subscribe to. Updates appear instantly across all devices.
Residents can add the HOA calendar to their personal calendar apps. They receive automatic reminders about upcoming events. They see at a glance when the pool closes for maintenance or when the annual meeting is scheduled.
The calendar reduces confusion and increases participation. When everyone knows about the community yard sale three weeks in advance, more families participate. When residents get reminders about the meeting to vote on the budget, attendance improves.
Implement a Maintenance Request System
Residents report problems through whatever channel seems easiest. One sends an email. Another calls a board member at home. Someone else posts on social media. A fourth resident stops the president in the parking lot.
This scattered approach loses information. The board member who received the call forgets to mention it at the meeting. The email gets buried in an overfull inbox. Nothing gets fixed and residents feel ignored.
A centralized maintenance request system captures every issue in one place. Residents submit requests through a simple online form. The system assigns a tracking number and sends automatic updates as the board addresses the problem.
Board members see all open requests in one dashboard. They can prioritize based on urgency, assign responsibility, and update status. Residents can check the status of their request anytime without calling or emailing.
Train Board Members on New Systems
Technology only helps if people know how to use it. Board members who feel overwhelmed by new systems will resist adoption or use tools incorrectly.
Schedule training sessions when implementing new technology. Many software providers offer free onboarding and training as part of their service. Take advantage of these resources.
Create simple how-to guides for common tasks. A one-page document with screenshots showing how to send a community announcement helps board members use the system confidently. Video tutorials work well for visual learners.
Start with one or two tools rather than implementing everything at once. Let board members become comfortable with digital communication before adding project management software. Build competence gradually.
Choose the Right HOA Management Software
Many companies offer all-in-one HOA management platforms that combine multiple tools into a single system. These platforms typically include payment processing, document storage, communication tools, violation tracking, and maintenance requests.
Popular options include Buildium, AppFolio, and CINC Systems. The Investopedia financial education site notes that integrated platforms often cost less than subscribing to multiple separate services.
When evaluating platforms, consider the size of your community, your budget, and which features matter most. A small HOA with simple needs may find a basic platform sufficient. A large community with complex requirements needs more robust capabilities.
Most platforms offer free trials or demonstrations. Test the system with a few board members before committing. Make sure the interface is intuitive and the customer support is responsive.
Address Privacy and Security Concerns
Moving to digital systems raises valid concerns about data privacy and security. Resident financial information, personal contact details, and private communications need protection.
Choose platforms that use encryption for data storage and transmission. Look for services that comply with recognized security standards. Read privacy policies carefully to understand how the company uses and protects information.
Establish clear policies about who has access to different types of information. Not every board member needs access to financial accounts. The landscaping committee does not need to see architectural review applications.
Use strong passwords and change them regularly. Enable two-factor authentication when available. These basic security practices prevent unauthorized access to association systems and data.
Get Resident Buy-In for Changes
Some residents resist change. They prefer receiving paper notices even if digital communication is faster and cheaper. They worry about technology they do not understand.
Communicate the benefits clearly. Explain how online payment saves residents time. Show how the community calendar helps families plan. Demonstrate that the new system makes it easier to get maintenance issues resolved.
Offer options when possible. Some platforms let residents choose whether they receive communications by email, text, or postal mail. This flexibility reduces resistance.
Provide support for residents who need help. Offer a tutorial session at the community center. Create simple instruction sheets for common tasks. Assign a tech-savvy volunteer to help neighbors who struggle with new systems.
Measure Results and Adjust as Needed
Technology should make life easier, not create new problems. Track whether new tools achieve their intended goals.
Monitor payment collection rates after implementing online payments. Did late payments decrease? Are processing costs lower? If the results disappoint, investigate why and make adjustments.
Survey residents about their experience with new communication tools. Are they getting the information they need? Is the website helpful? Use feedback to improve systems.
Review board member time spent on administrative tasks. If technology was supposed to save time but board members feel busier than ever, something went wrong. Identify bottlenecks and streamline processes.
Technology should serve your community’s needs, not create new burdens. Choose tools that solve real problems and make everyone’s life easier. Your HOA will run more smoothly and residents will appreciate the improvements.
Bring Your HOA Into the Modern Age With Technology and Modern Practices was last modified: July 17th, 2026 by Thomas M
Modern professionals rely on dozens of online platforms every day. Customer relationship management (CRM) systems, cloud storage, communication apps, project management software, and collaboration tools all play an important role in keeping businesses productive. As the number of digital services continues to grow, managing accounts securely has become just as important as choosing the right software.
Efficient account management improves productivity by reducing unnecessary login issues, simplifying access to business applications, and protecting sensitive information. Organizations that develop consistent security practices often experience fewer disruptions while maintaining better control over employee access across multiple platforms.
When businesses evaluate new cloud services or productivity applications, phone verification is often required during registration. Solutions such as Confirmed Accounts SMS Verification can assist with temporary SMS verification for eligible one-time registrations, providing a practical option for activating evaluation accounts or project-specific services without using a primary business phone number for every new platform.
Why Digital Account Management Matters
Every online service creates another account to manage. Without a structured approach, organizations can quickly accumulate inactive accounts, duplicate credentials, and unnecessary security risks.
Good account management helps organizations:
Reduce password-related issues.
Improve employee productivity.
Strengthen account security.
Simplify software administration.
Support regulatory compliance.
Minimize unauthorized access.
Small improvements in account organization often produce long-term operational benefits.
Essential Security Practices for Modern Businesses
Businesses should establish clear standards for managing employee accounts across all digital platforms.
Best Practice
Business Benefit
Multi-factor authentication
Adds stronger login protection
Role-based permissions
Restricts unnecessary access
Password managers
Improves credential security
Regular account reviews
Removes inactive users
Login monitoring
Detects unusual activity
These practices reduce security risks while making day-to-day administration more efficient.
Choosing Productivity Software Wisely
Not every business application offers the same level of usability, integration, or security. Before introducing a new platform, organizations should evaluate several important factors.
Integration Capabilities
Applications that connect with CRM systems, calendars, cloud storage, and communication tools eliminate duplicate work while improving data consistency.
Ease of Adoption
Simple interfaces reduce employee training time and encourage broader adoption across teams.
Security Features
Organizations should prioritize platforms that support encryption, secure authentication, and transparent privacy policies.
Improving Team Productivity Through Better Organization
Technology should simplify workflows rather than create unnecessary complexity. Businesses that establish clear digital processes often spend less time troubleshooting software and more time focusing on strategic objectives.
Helpful productivity habits include:
Reviewing user permissions quarterly.
Removing unused software accounts.
Standardizing approved business applications.
Documenting software ownership.
Updating recovery information regularly.
Encouraging secure password practices.
These routines improve operational consistency while reducing administrative overhead.
Supporting Remote and Hybrid Work
Remote work has increased the importance of secure, cloud-based collaboration. Employees frequently access business systems from multiple locations and devices, making consistent account management more valuable than ever.
Organizations supporting distributed teams should consider:
Centralized Access Management
Managing user accounts from a central location simplifies onboarding, offboarding, and permission updates.
Secure Authentication
Layered authentication reduces the risk of unauthorized access without significantly affecting employee productivity.
Regular Security Awareness
Employees who understand phishing, password security, and account protection contribute to a stronger security culture.
As organizations continue adopting flexible work models, BBC Worklife's coverage of workplace trends often explores how technology is changing collaboration, leadership, and employee productivity across industries.
Building Sustainable Digital Workflows
Productivity depends on more than selecting powerful software. Organizations also benefit from consistent processes that keep accounts secure, organized, and easy to manage throughout their lifecycle.
By combining thoughtful account management, secure verification practices, and carefully selected productivity tools, businesses can reduce operational friction while creating a more reliable digital environment. As organizations continue embracing cloud technologies and connected workflows, effective account management will remain a key factor in long-term business efficiency and digital resilience.
Streamlining Digital Productivity With Smarter Account Management Practices was last modified: July 14th, 2026 by Jay Stone
Navigating the world of modern technology infrastructure requires a strategic partner who can protect your digital assets. Entrusting your corporate network to external professionals allows your internal teams to focus entirely on core business objectives. This article outlines the criteria you need to analyse to ensure your chosen technology provider supports commercial success and operational resilience.
Analysing Proactive Maintenance Protocols
To safeguard your digital ecosystem effectively, assess whether a prospective technology provider focuses heavily on preventing system disruptions. A high-quality support partner relies on continuous remote monitoring tools that scan your infrastructure around the clock for hidden vulnerabilities. This continuous oversight resolves minor hardware glitches silently before they escalate into costly ones.
Assessing Cybersecurity Defence Frameworks
Protecting confidential company data and sensitive client information requires multi-layered security. You need to investigate whether a provider implements advanced threat detection tools and automated data encryption standards across your entire network. A competent managed it services firm will conduct assessments to discover potential entry points for malicious software and phishing attempts.
Reviewing Service Level Agreement Commitments
Understanding how a technology firm will respond when a critical system failure occurs is vital for maintaining business continuity. A robust service contract should define response times for varying levels of technical urgency, ranging from minor software queries to network outages. Look for guarantees regarding system uptime and clear financial remedies if those performance baselines are not met.
Evaluating Data Backup and Recovery Systems
Experiencing a hardware malfunction or a severe digital breach can result in permanent information loss unless a comprehensive duplication strategy is running. Verify that your chosen partner performs automated, off-site data backups at frequent intervals. Furthermore, the technical team must routinely test the restoration process to guarantee that your systems can be recovered during an emergency.
Verifying Scalability and Strategic Planning Support
As your enterprise expands its market presence, your technological requirements will become more complex. A premium service provider acts as a virtual technology officer, offering strategic reviews to align your computing infrastructure. They should assist you in forecasting software licensing demands, planning hardware replacement cycles, and integrating flexible cloud computing solutions seamlessly.
Inspecting Infrastructure Monitoring Capabilities
Maintaining peak operational speed requires an infrastructure team that tracks the real-time health of your servers, cloud databases, and local network connections. Automated monitoring systems should alert technicians the moment a network switch slows down. This insight allows engineers to optimise network traffic flow and allocate computing resources to ensure your staff experience zero software lag.
Investigating Helpdesk Expertise and Support Culture
The daily productivity of your staff depends heavily on how easily they can access friendly technical assistance when minor computer glitches arise. Ensure the support desk employs professionals who explain technical solutions simply. A support structure that offers multiple contact channels, including direct phone lines and rapid ticketing systems, ensures quick resolutions for everyday user frustrations.
Examining Cloud Integration and Migration Competency
Migrating local databases to secure remote networks requires an engineering team that specialises in seamless digital transitions. You need to confirm that your prospective partner possesses certified expertise in managing cloud platforms and configuring remote user permissions safely. This proficiency ensures your remote staff can collaborate on complex corporate files securely from any location.
Cultivating a Secure and Resilient Digital Future
Selecting the right technological partner forms the foundational bedrock of a modern enterprise. By choosing a managed services provider that aligns with your goals, you secure the specialised expertise needed to thrive in a digital marketplace. Committing to a thoroughly vetted technology partnership empowers your business to scale confidently, securely, and without technological limitations.
How to Evaluate Managed it Services for Secure Business Growth was last modified: July 13th, 2026 by Alfie Frenilla
The word “smart” appears on everything from kitchen appliances to watches, heating systems, and sports equipment. Yet the most useful smart devices are not defined by touchscreens or mobile apps alone. Their real value comes from the ability to observe what is happening, process that information, and respond in a way that makes an ordinary task easier or more precise.
Sensors provide awareness. Software gives the collected information meaning. Together, they allow devices to measure movement, temperature, pressure, location, energy use, and countless other conditions that once required human observation. This shift is quietly changing everyday routines. Golfers can examine individual shots within seconds, homeowners can understand how heating patterns change throughout the day, and appliances can adjust their operation according to real conditions. The smartest technology is increasingly the technology that works in the background while helping people make better decisions.
Sports Equipment Is Turning Physical Movement Into Useful Data
Athletes once relied primarily on feel, repetition, and a coach’s observation to understand performance. Those methods remain important, but sensors can now capture details that are almost impossible to judge accurately with the naked eye. Cameras, radar, and motion tracking systems measure tiny changes in speed, angle, direction, and impact, turning a brief physical action into information that can be reviewed repeatedly.
Golf provides a particularly clear example. Modern portable launch monitors can measure elements such as ball speed, spin, launch angle, carry distance, and club movement during practice. The important development is not simply that these measurements exist. Software can organize the readings shot by shot, helping players identify patterns instead of judging an entire practice session from a few memorable swings. A golfer who consistently loses distance with one club can investigate the data rather than relying entirely on guesswork.
This approach is appearing across sport. Running watches examine pace and movement, cycling computers record power output, and connected fitness equipment tracks consistency between sessions. Sensors do not perform the activity for the athlete, but they make previously invisible details easier to recognize.
Smart Homes Are Learning to Respond to Real Conditions
Home technology has followed a similar path. Older household controls generally depended on direct instructions: turn something on, select a setting, and turn it off later. Smart devices can use sensors and software to respond to conditions that change throughout the day, reducing the need for constant manual adjustments.
Temperature control demonstrates how practical this can become. Someone comparing the best home smart thermostat is no longer looking only at the number displayed on the wall. Compatibility, scheduling, humidity sensing, energy tracking, room data, and smart-home integration can all influence how effectively a system manages comfort. Software may display historical runtime information or coordinate a heating schedule, while sensors provide the measurements needed to make those features useful.
The same principle applies elsewhere in the home. Lights can react to movement, irrigation systems can consider environmental conditions, and security devices can distinguish between different types of activity. These products become valuable when automation removes repetitive decisions without making basic controls confusing. A device that requires constant app management may technically be connected, but it has not necessarily made the home easier to manage.
Better Software Turns Measurements Into Decisions
Photo by Daniel Romero on Unsplash
Collecting information is relatively easy compared with explaining what that information means. A device can generate thousands of measurements, but raw numbers have limited value if the user cannot identify which ones deserve attention. This is where software has become central to the development of smarter products.
Good software filters, compares, and presents data in a form that supports a decision. A fitness device might show that sleep duration has changed over several weeks rather than forcing the user to compare individual nights manually. An energy application can reveal when consumption is consistently highest. Sports software may group repeated measurements and highlight trends that would be difficult to notice during practice.
The design of these systems matters. More data does not automatically create a better experience. When dashboards contain dozens of unexplained metrics, users can become less confident rather than more informed. Effective devices prioritize the information most relevant to the task and allow deeper analysis when it is genuinely needed.
This explains why software updates can significantly change a physical product after purchase. Improved algorithms, clearer interfaces, and better integrations can make existing sensors more useful without changing the hardware itself. The device remains physically identical, but its ability to interpret and communicate information improves.
Automation Works Best When It Reduces Repetitive Choices
The strongest smart devices often become almost invisible during everyday use. After initial setup, they handle predictable tasks and ask for attention only when something unusual happens. This is a major change from early connected products, which sometimes seemed designed to send a notification for every minor event.
Useful automation begins with understanding routine behavior. A device may follow a schedule, react to a sensor reading, or combine several conditions before taking action. The purpose is not to remove human control but to reduce the number of repetitive choices people make throughout the day. Adjusting the same setting every morning is a good candidate for automation; making an unusual or high-impact decision usually still benefits from human input.
There is also a balance between personalization and predictability. Some users appreciate systems that learn behavior automatically, while others prefer creating precise schedules themselves. Smart technology works best when people understand why a device is acting and can easily change its behavior. Automation that constantly surprises the owner quickly becomes frustrating, regardless of how advanced the underlying software may be.
Manufacturers are gradually recognizing that simplicity is a feature. Clear controls, understandable settings, and reliable routines can matter more than an enormous list of experimental functions. The smartest product is often the one that solves a familiar inconvenience consistently.
The Next Generation of Devices Will Be Defined by Context
Sensors are becoming smaller, more accurate, and easier to include in ordinary products. At the same time, software is becoming better at comparing multiple streams of information. The result will likely be devices that respond less to single measurements and more to context.
A sensor detecting movement can provide one piece of information. Combine movement with time, temperature, location, and previous patterns, and software gains a much clearer picture of what may be happening. This broader context can help devices avoid unnecessary reactions and provide information at more useful moments.
However, smarter products will also face greater expectations around privacy, reliability, and control. Consumers may appreciate personalization while still wanting to understand what information a device collects and where it is processed. A convenient feature can quickly lose its appeal if users feel they have little control over their own data or cannot operate basic functions without an internet connection.
The future of smart devices therefore depends on more than adding sensors to additional products. Successful technology must collect the right information, interpret it clearly, and use it to solve a genuine problem. Golf equipment, thermostats, watches, appliances, and countless other devices are already moving in this direction.
When sensors provide accurate awareness and software turns that awareness into practical action, ordinary objects become more useful without demanding more attention. That quiet improvement, rather than another screen or notification, is what increasingly defines a genuinely smart device.
How Sensors and Software Are Making Everyday Devices Smarter was last modified: July 13th, 2026 by Prester Witzman
Sooner or later someone hands you a .pst file and asks you to read what is inside, and there is no copy of Outlook on the machine in front of you. Maybe you inherited an old mailbox export, a colleague left the company, or you are on a Mac or a Linux box that never had Outlook installed. Because the PST format is tied to Microsoft Outlook, the file can look like a dead end without that program. It is not. You can turn the messages inside a PST into ordinary PDF files that open on any device, and you do not need to reinstall Outlook to do it.
PDF is a sensible target for a few reasons. Every phone, tablet, and computer can open a PDF without special software, each message keeps its formatting and headers, and once a message is a PDF you can search it, print it, or attach it to a ticket like any other document. Converting a mailbox to PDF also lets you share a handful of specific emails with someone without giving them the entire archive, which is hard to do while everything stays locked inside a single Outlook file.
The quick way: convert online
When you have one PST and just need the emails out of it, the fastest route is to convert PST to PDF in the browser. You upload the file, the service reads the messages, and you download the PDFs. There is nothing to install and no account to create, so it behaves the same on Windows, macOS, or Linux. This is the right choice for a one-off job or when you are working on a computer you do not control and cannot add software to.
The scalable way: a desktop converter
If the PST is large, or you have several of them, a desktop tool handles the volume better. The CoolUtils Total Mail Converter opens a PST directly, without Outlook, and exports every message to its own PDF in a single run. It works on Windows 7 through 11 and lets you name the output files by date, sender, or subject so the folder stays readable instead of filling up with generic file names. For repeat jobs it includes a command-line interface, which means you can point it at a folder of PST files and let it process them unattended, or wire it into a script that runs on a schedule. A 30-day trial is available with no credit card required, so you can convert a real mailbox before deciding.
Keeping the data private
Mailboxes often hold sensitive correspondence, so where the conversion happens matters. An online converter is convenient, but the file is uploaded to a server, so it suits non-confidential archives or messages you would be comfortable emailing anyway. When the content is private, the desktop tool is the safer option because the PST never leaves your computer: the conversion runs locally and the PDFs are written straight to a folder you choose. For regulated data, that local processing is usually a requirement rather than a preference.
A few things to check
If the PST is password-protected, have the password ready; no converter can read a locked file without it.
Decide up front whether you need attachments saved separately or embedded in each PDF.
For very large archives, convert in batches by folder so the job is easy to verify afterward.
Conclusion
A PST file without Outlook is not a dead end. For a single archive, an online converter gets the emails into PDF in a few clicks on any operating system. For bigger or recurring jobs, a desktop converter with a command-line mode does the same thing at scale and keeps everything on your own machine. Either way, the messages become plain PDFs you can read, search, and share without touching Outlook.
How to Convert PST Files to PDF Without Outlook was last modified: July 8th, 2026 by Colleen Borator
At the start of a business launch, off-the-shelf CRM systems are the obvious choice. They’re fast to deploy, come with ready-made templates, and require no deep technical expertise. That’s exactly why platforms like Salesforce and HubSpot became the default for small and mid-sized businesses.
But once a company scales — new markets, more complex logistics, more layered finance models — a one-size-fits-all SaaS solution starts to slow growth down.
According to 2025 industry data, more than 62% of companies hit hard limits with their standard CRM within three to five years of implementation. The recurring issues are:
Limited flexibility around custom fields
Rigid workflow scenarios
Complexity of deep CRM integration with ERP, billing, and logistics
Heavy dependence on third-party plugins
As a result, the CRM — meant to be a sales engine — turns into the weakest link in the company’s data architecture.
The Data Silo Problem
Most scaling enterprises operate with sales running on a CRM, finance on an ERP, logistics on its own platform, and marketing on a separate automation tool. When synchronization between these systems isn’t configured correctly, data silos form.
That fragmentation creates predictable risks:
Outdated transaction statuses
Duplicate contact records
Conflicting versions of the same data
Lost history of client interactions
In many cases, sync ends up one-directional: the CRM pushes data to the ERP but never receives updates back. A manager sees an order marked “paid,” while the finance system still shows the payment as pending.
According to Forrester research, by early 2026 companies with fragmented systems had lost up to 18% of potential revenue due to data errors and communication delays between departments.
As a company grows, so does the complexity of its IT landscape. ERP, billing, warehouse management, marketing automation, support tools, and BI platforms all get added around the CRM. Each system solves its own problem — but lives its own isolated life. That’s how data silos form: arrays of information that are unsynchronized or only partially synced.
On paper, that looks manageable. In practice, it breaks down the moment all that data needs to work together:
The CRM shows a deal in its final stage
The ERP hasn’t confirmed payment yet
Logistics never received the updated status and doesn’t release the shipment
The client has no idea why their order is delayed
Every system is technically “working,” but there’s no single source of truth connecting them. Research shows companies with disconnected data flows spend up to 20% of operational time on manual reconciliation between departments alone.
This fragmentation doesn’t just slow down day-to-day operations — it undermines strategic decision-making. When leadership sees three different revenue numbers across three systems, it becomes far harder to confidently decide on market expansion, new product launches, sales investment, or workflow automation. Analysts estimate that companies with fragmented data make strategic decisions up to 30% slower, simply because of the extra verification and approval cycles required.
Data silos aren’t a minor technical inconvenience — they’re a structural barrier to scaling. Without rebuilding CRM integration at the level of a full enterprise data architecture, the problem keeps resurfacing.
The Case for Custom CRM Architecture
Once a business outgrows standard processes, simple CRM customization isn’t enough — it needs a full custom architecture built around it.
The core principle: build the system around your business processes, not the other way around. A custom CRM architecture allows a company to:
Design a flexible data model
Encode specific business rules directly into the system
Automate complex workflows without relying on workarounds
Maintain a transparent, unified data architecture across departments
Generic platforms tend to struggle with complex, multi-layered data workflows. As an organization grows, the case for bespoke CRM infrastructure becomes obvious — a custom-built system acts as the central nervous system of the enterprise, keeping every record synchronized across departmental silos without the lag or conflicts typical of bolted-on plugins.
Understanding the full custom CRM development cost upfront — rather than discovering it through years of plugin fees and workarounds — is usually what tips the decision in favor of a purpose-built system. In practice, a custom CRM becomes the synchronization point where sales, finance, analytics, and operations all converge.
Why Bi-Directional Sync Is a Must-Have
The backbone of any scalable enterprise system is bi-directional synchronization — data updating in both directions at the same time. When a payment status changes in the ERP, the deal stage updates in the CRM automatically. When a manager updates a client’s contact details in the CRM, the billing system reflects the change instantly.
No delays, no duplication risk, no version conflicts.
Full bi-directional sync relies on a handful of core principles, built around API-first design and event-driven architecture:
API-first approach — every system communicates through stable, documented APIs.
Event-driven architecture — a change in one system triggers events that propagate instantly to the others.
Version control and logging — every update is tracked to prevent conflicting writes.
Conflict resolution rules — when simultaneous changes happen across systems, the architecture defines which source of truth takes priority.
For enterprises handling high-velocity transactions, secure financial data synchronization frameworks aren’t optional — they’re what keeps billing systems and legacy cores talking to each other without delay. This kind of investment typically cuts operational errors by 35-40% and lays the groundwork for long-term scalability.
Most enterprises are now moving toward real-time synchronization, since even a 5-10 minute lag can cost transactions. This becomes critical during legacy system migrations, where any sync error can wipe out transaction history or break the chain of client interactions.
Companies with full bi-directional sync in place report a 35-40% drop in operational-error-related incidents on average. Beyond the technical upside, they gain real-time control over their data — which translates directly into a competitive edge.
The Economic ROI
Custom CRM architecture isn’t just a technical upgrade — it’s a financial one. The return shows up in a few concrete ways:
Fewer human errors. Automated bi-directional sync minimizes manual data entry, and less manual work means fewer mistakes. Estimates put the reduction in operational errors from CRM integration at 30-45%.
Faster sales cycles. Managers work from a single, current source of truth, with financial and logistics statuses visible in real time. For B2B companies with complex contracts, this shortens the sales cycle by 15-22% on average.
Scaling without rebuilding. When client volume doubles or triples, an off-the-shelf CRM often forces a costly rebuild or a stack of expensive add-on modules.
True horizontal scaling. A custom system built on solid data architecture lets you add new modules, departments, and regions without touching the core.
Conclusion
The future belongs to integrated ecosystems where data moves freely between systems — no silos, no lag, and a measurable economic upside as a result. Modern commerce simply can’t run on fragmented systems and one-directional sync anymore.
Custom CRM architecture with full bi-directional synchronization isn’t a luxury — it’s a technical necessity for companies serious about scaling. Companies like Merehead, which specialize in building this kind of infrastructure, have seen firsthand that the companies investing in proper CRM integration and data architecture today are the ones locking in a strategic advantage for years to come.
The Hidden Cost of Data Silos: How Bi-Directional CRM Sync Powers Enterprise Growth was last modified: July 1st, 2026 by Colleen Borator
AI wearables are quickly moving from consumer gadgets into serious business tools. For professionals, the appeal is easy to understand. People want faster access to information, smoother communication, fewer interruptions, and technology that supports work without constantly pulling them back to a phone or laptop.
That is why Ray-Ban AI glasses fit into a much larger workplace trend. Smart glasses and other AI-powered wearables are becoming part of a new productivity ecosystem where workers can capture information, receive assistance, communicate, and multitask with less friction.
For business users, the question is no longer whether wearable technology is interesting. It is how these devices can support real work in practical, responsible, and measurable ways.
AI Wearables Are Changing Workplace Productivity
Productivity is not only about working faster. It is also about reducing small interruptions that slow people down. Every time a professional stops to unlock a phone, search for information, take notes, check a message, or document a task, attention is broken.
AI wearables can reduce some of that friction. A smartwatch can surface quick alerts. Smart earbuds can support calls and voice commands. Smart glasses can help with hands-free capture, audio assistance, real-time prompts, and quick access to information.
Deloitte’s discussion of wearable devices in the workplace notes that wearables can enhance worker effectiveness, support productivity, and help improve safety. That business value is one reason companies continue to explore wearable tools across different industries.
The strongest use cases are not about replacing existing devices. They are about making certain tasks easier to complete without disrupting the flow of work.
Why Smart Glasses Are Useful for Communication
Communication is one of the most obvious workplace uses for smart glasses. Professionals already rely on video calls, voice notes, messaging apps, and quick updates throughout the day. Smart glasses make some of these interactions more natural because they support hands-free use.
For example, a field worker can share a first-person view with a remote expert. A technician can document a repair step without holding a phone. A manager walking through a site can capture a quick note or communicate while staying aware of the environment.
This point-of-view communication is especially useful in industries where workers need both hands available. Construction, logistics, healthcare support, manufacturing, inspections, events, and training can all benefit from tools that reduce the need to stop and handle another device.
Smart glasses can also make communication feel less screen-heavy. Instead of switching between a laptop, phone, and meeting app, users can rely on audio, voice control, and quick commands for simpler interactions.
Real-Time Information Access Matters
Business users often need information at the exact moment they are making decisions. That might mean checking a procedure, confirming a product detail, translating a phrase, reviewing instructions, identifying an object, or asking for a quick summary.
AI-powered wearables can help by bringing information closer to the task. Instead of stepping away to search on a phone or computer, a user may be able to ask a question, hear a response, or capture context in real time.
This is where smart glasses become especially interesting. Because they are worn at eye level, they can support more contextual experiences. The device can capture what the user is seeing, while AI features can help interpret or respond to that information.
In business settings, that can support faster decisions, better documentation, and more efficient collaboration.
Hands-Free Technology Supports Different Industries
Hands-free technology is valuable anywhere movement matters. In offices, it may help with calls, reminders, notes, and quick information access. In field-based jobs, it can support documentation, remote guidance, safety checks, and training.
For logistics workers, wearables may help with picking, scanning, routing, and task updates. For technicians, they can support repair guidance and remote troubleshooting. For healthcare-adjacent teams, smart glasses may help with communication, workflow documentation, or training, depending on privacy and compliance rules.
In retail and hospitality, wearable technology can help employees access information without leaving customers waiting. In education and training, smart glasses can support demonstrations, recorded walkthroughs, and immersive learning.
The common thread is convenience. Workers can stay engaged with the task while technology supports them in the background.
AI Wearables Can Help With Multitasking
Multitasking is often messy. People jump between screens, apps, calls, notes, and physical tasks. AI wearables can make some multitasking more manageable by handling small tasks quickly.
A professional may use voice commands to set a reminder, capture a photo, start a recording, answer a call, or ask for information. These actions may seem small, but they can save attention over the course of a busy day.
Microsoft’s 2026 Work Trend Index reports on how AI is reshaping work and how organizations are thinking about human agency, AI assistance, and new workflows. Its report on AI and the future of work reflects the broader shift toward AI-supported productivity, where technology helps people focus on higher-value decisions instead of constant execution.
For wearables, the goal should be similar. The best devices will not simply add more notifications. They will reduce unnecessary steps and help users stay focused.
Business Adoption Will Depend on Trust
AI wearables have strong potential, but adoption will depend on trust. Businesses need to think carefully about privacy, data security, recording policies, employee consent, and customer comfort.
Smart glasses with cameras require clear rules. Where can recording happen? Who has access to captured content? How is data stored? What happens in sensitive environments? These questions matter, especially in workplaces where customers, patients, employees, or confidential information may be involved.
Companies also need to avoid using wearables in ways that feel intrusive. Productivity tools should support workers, not make them feel constantly monitored. Transparency will be important if businesses want employees to adopt wearables willingly.
The companies that succeed with AI wearables will be the ones that treat them as workflow tools, not surveillance tools.
Why Adoption Is Expected to Grow
Business adoption of wearable technology is expected to grow because the underlying problems are not going away. Workers need faster access to information. Companies need better documentation, training, communication, and safety tools. Professionals want less screen friction and more flexible ways to stay productive.
At the same time, wearable hardware is improving. Devices are becoming lighter, more stylish, more comfortable, and more capable. AI software is also becoming more useful, especially for voice interaction, summaries, translation, visual assistance, and real-time guidance.
As the technology becomes easier to use, more businesses will test it in focused ways. The early wins will likely come from specific use cases: remote support, field documentation, training, logistics, inspections, and hands-free communication.
Final Thoughts
AI wearables are becoming more relevant for business users because they solve practical problems. They can reduce friction, support hands-free work, improve communication, provide real-time information, and help professionals stay focused while moving through busy tasks.
Smart glasses are especially important because they combine voice, audio, camera features, and AI support in a wearable format that fits naturally into many work environments.
The future of business wearables will not be about adding technology for its own sake. It will be about using the right devices to make work simpler, safer, faster, and more connected.
The Rise of AI Wearables: What Business Users Need to Know was last modified: June 30th, 2026 by Juliette Habetz