Most small businesses handle customer support the same way for the first few years: a shared inbox called support@company.com with three or four employees CC’d. It works fine until it doesn’t. Around the five-agent mark, the same customer question gets answered twice by different people. A reply gets missed for three days because it landed in someone’s personal folder. A refund promise from Tuesday becomes a refund dispute on Friday because no one logged the conversation. The cost of growing past this point without proper tooling shows up quietly in your retention numbers.
This guide covers customer support software for small business in 2026. Not the enterprise-focused reviews that compare Zendesk Suite pricing tiers. The practical version for small businesses that are still on Outlook or Google Workspace, running Act! or Pipedrive, and not willing to sign a $30,000 annual contract to answer customer email.

Why small businesses need real customer support software
A shared email inbox works for the first twenty customers. It breaks around customer number two hundred. The symptoms are predictable.
Response times double or triple. When nobody owns a conversation, everyone assumes someone else will handle it. Customers wait hours or days. For SMB ecommerce and service businesses, response time is the single strongest predictor of whether a customer buys again.
Duplicate and contradictory replies. Two employees answer the same question without knowing the other answered. One offers a refund, the other offers a 10% discount. The customer screenshots both and posts it on social.
No accountability. Who is working on what right now? Shared inboxes have no concept of “assigned” or “in progress” or “waiting on customer.” Everything is either bolded or not bolded.
No visibility for the owner. The small business owner has no idea if the team is hitting a 2-hour response time or a 2-day response time. You cannot improve what you do not measure.
No mobile support. Outlook on the phone works for reading personal email. It does not work for answering 40 support threads while walking through the warehouse.
A real customer support platform fixes all five problems with the same product. That is why the category exists and why it becomes essential somewhere between 5 and 15 employees.
Features to look for in customer support software for small business
Not every small business needs every feature. The core list that separates a real customer support platform from a glorified shared inbox is short.
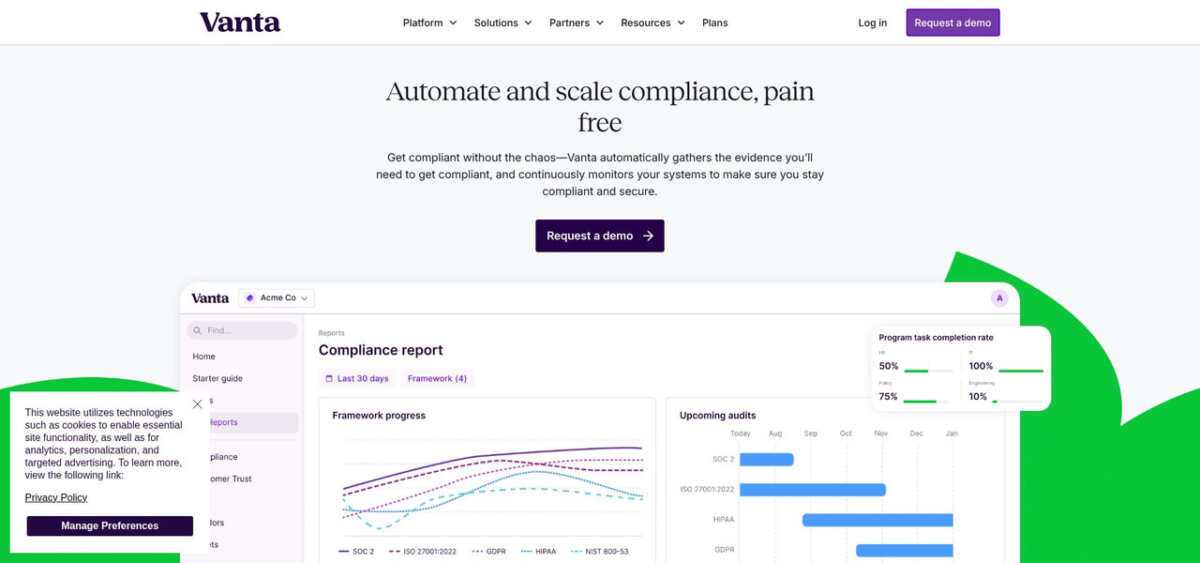
Shared inbox with ownership and status. Every incoming email, chat message, or WhatsApp conversation is a ticket. Each ticket has an assigned agent, a status (open, pending, resolved), and a timestamp history. Nothing falls through.
Multi-channel support. Email is the baseline. Live chat on the website, WhatsApp Business, Telegram, SMS, and social DMs are increasingly table stakes. Platforms that gate channels behind upgrade tiers are expensive trap doors for growing teams.
Automation rules. When a ticket contains “refund”, assign to the finance team. When a ticket comes from a VIP customer, escalate to the owner. Basic rule-based automation reduces support work by 30 to 50 percent once tuned.
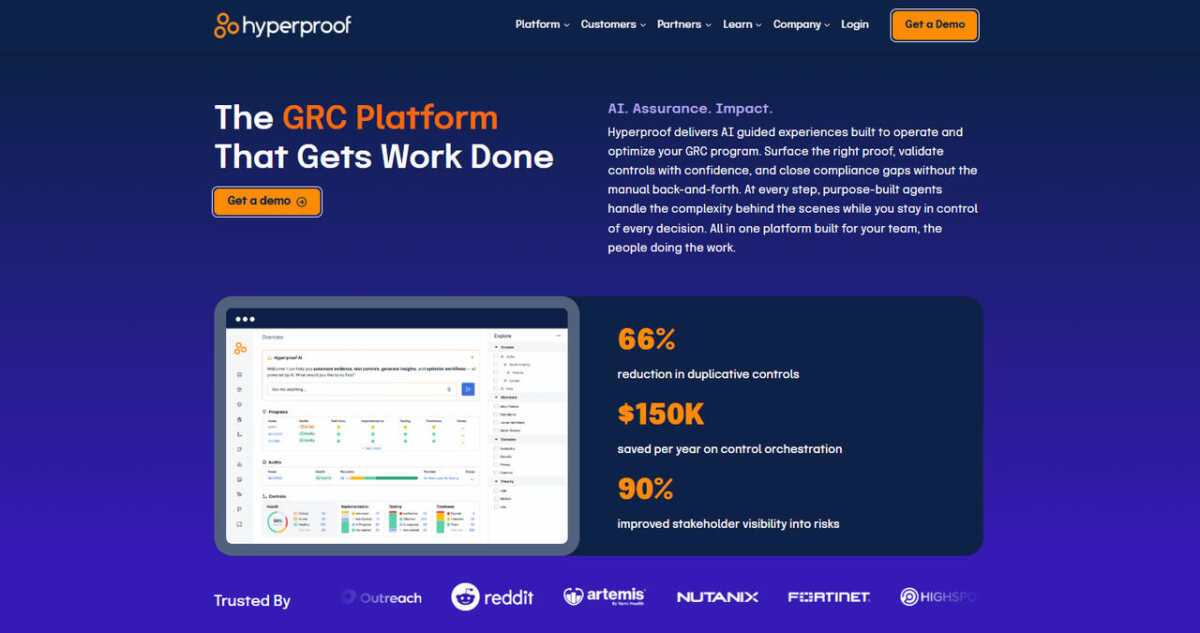
AI chatbot and Copilot. The 2026 standard. The AI chatbot answers routine questions (shipping, returns, hours) without human intervention. The AI Copilot drafts replies for the human agent based on past conversations and connected CRM data. A small business running one of these well can handle the workload of a team twice its size.
Knowledge base. A searchable collection of help articles that customers find via Google or in the chat widget. Deflects 30 to 50 percent of inbound support for teams that populate it well.
CRM and commerce integration. If you run Outlook for email, Pipedrive for leads, Shopify for orders, and Stripe for billing, your support software needs to pull context from all of them. No agent should have to tab between five tools to answer one ticket.
Mobile app. Push notifications on the owner’s phone the moment a VIP customer writes in. A proper native app, not just a responsive website.
Transparent pricing. Per-agent pricing that does not balloon when you add a seat or a channel. Enterprise platforms famously quote $19 per agent, then add $30 for AI, $25 for WhatsApp, and $40 for advanced reporting. The real cost is often 4x the sticker price.
Top 5 customer support software for small business in 2026
Five platforms worth shortlisting. Each is ranked with the use case it fits best and the real price you pay at small-team scale.
1. Deskwoot.com
Best for: small businesses and growing teams that outgrew a shared inbox and want everything included without add-on creep.
Deskwoot positions itself as affordable customer support software for SMBs. Per-agent pricing starts at $4.50 per month. AI Copilot and eight channels (email, live chat, WhatsApp, Telegram, LINE, SMS, X, and a REST API channel for custom integrations) are included in every paid plan rather than sold as modules. The AI Bot costs $0.01 to $0.03 per conversation, compared to $0.99 to $2.00 per resolved ticket on the enterprise platforms.
Native integrations with Shopify, WooCommerce, Stripe, and Zapier make it fit the typical small business stack without custom development. A free plan covers solo founders.
2. Zendesk Support Suite
Best for: mid-market teams that have the admin capacity and budget for a full-featured enterprise help desk.
Zendesk is the most mature customer support platform on the market. The ticketing system is deep, automation is flexible, and reporting is comprehensive. The trade-off is price and complexity. Entry pricing starts at $19 per agent per month; the Enterprise Suite is $115 per agent per month. AI Copilot is a $50 per agent add-on. Configuration usually requires a dedicated admin or paid implementation partner.
Small businesses often find Zendesk overpriced for their actual needs once the add-on math is done. Teams under 25 agents typically benefit more from a simpler platform.
3. Freshdesk
Best for: budget-conscious small businesses comfortable with feature-gated tiers.
Freshdesk has a usable free plan and starting tier at $15 per agent per month. The trouble appears in higher tiers where WhatsApp becomes an add-on, Freddy AI is a paid module at $29 per agent, and live translation is gated. Total cost at mid-market scale frequently rivals Zendesk.
4. Help Scout
Best for: email-first teams that want a cleaner alternative to Zendesk without many channels.
Help Scout has a reputation for elegant product design and a small-team focus. Pricing starts at $25 per agent per month. The catch: live chat is a bolt-on, no native WhatsApp, and AI capabilities lag behind Deskwoot, Zendesk, and Intercom.
5. Crisp
Best for: very small teams that live inside a website live chat widget.
Crisp charges per workspace ($45 to $295 per month) regardless of team size. For solo founders and tiny teams, that pricing model can feel generous. For teams that need AI chatbot, SLA policies, or automation at scale, Crisp’s lack of those features becomes a cap.
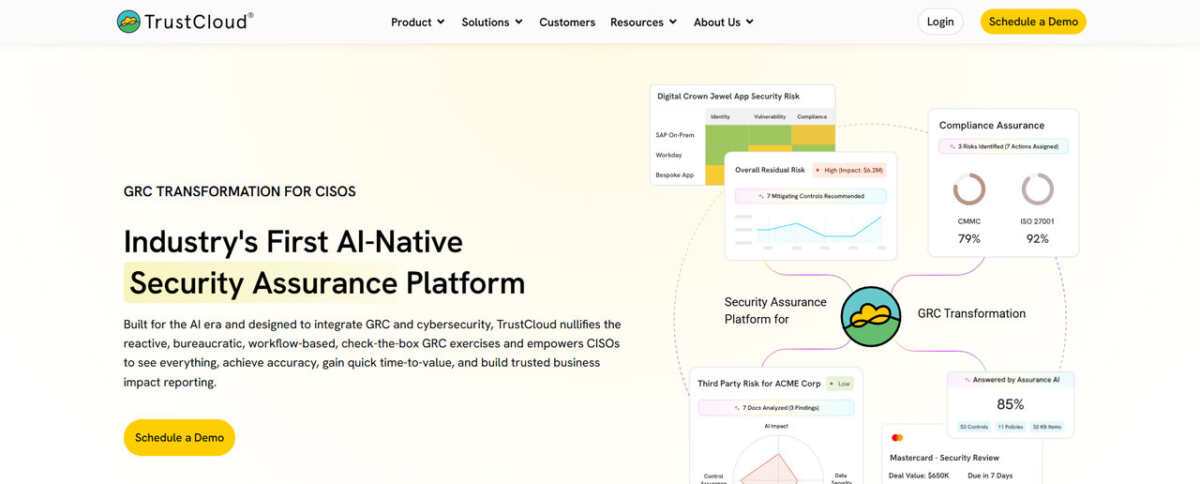
Customer support software comparison for small business
A snapshot of the dimensions that actually matter at small-business scale.
- Starting price per agent: Deskwoot $4.50, Freshdesk $15, Zendesk $19, Help Scout $25, Crisp $45/workspace
- AI Copilot included: Deskwoot yes; Zendesk no (+$50/agent); Freshdesk no (+$29/agent); Help Scout partial; Crisp no
- AI chatbot cost per conversation: Deskwoot $0.01 to $0.03; Zendesk $1.50 to $2.00; Intercom Fin $0.99; Freshdesk Freddy $0.10
- WhatsApp in base plan: Deskwoot yes; Zendesk yes; Freshdesk add-on; Help Scout no; Crisp yes
- One-click migration from Outlook / Gmail shared inbox: Deskwoot yes; Zendesk partial; Freshdesk partial; Help Scout yes; Crisp no
- Native iOS app: Deskwoot yes (free); Zendesk yes; Freshdesk yes; Help Scout partial; Crisp yes
How to migrate from Outlook or Gmail shared inbox
The single biggest objection small businesses raise when moving off a shared inbox is the fear of disruption. The actual migration is less painful than most owners expect.
Step 1: Forward the support address. Set up email forwarding from support@yourcompany.com to the intake address the new platform provides. All new emails now land in both your old inbox and the new tool. Nothing breaks.
Step 2: Pilot with two agents for a week. Those two agents answer from the new platform. The rest of the team keeps using Outlook. You validate that the new workflow handles edge cases: attachments, signed-for packages, Cc threads.
Step 3: Import the historical customer data. Modern platforms support CSV import of contacts from Outlook or a CRM. You can also sync contacts automatically through tools designed for cross-system data sync. If you use Pipedrive, Salesforce, or Act!, check for native integrations before committing.
Step 4: Switch the whole team. Once the pilot is smooth, switch the remaining agents. Turn off email forwarding after a week of the new tool being primary. Archive the old shared inbox.
Step 5: Connect your commerce and CRM. Shopify orders, Stripe invoices, Outlook calendar invites, Google contacts. Each integration reduces tab-switching and speeds up resolution.
Most small business migrations take two to four weeks from signup to full team adoption.
Budget considerations for small business customer support software
Price is the loudest decision driver at small-business scale. Two hidden costs beat the sticker price.
Per-resolution AI pricing. If the platform charges per AI-resolved ticket (Intercom Fin, Zendesk Fin), your bill grows with customer volume. A viral moment, a holiday peak, or a product launch can 10x the support cost in a month. Flat per-conversation pricing (Deskwoot) or bring-your-own-key options stay predictable.
Feature-gated tiers. A $15 per agent plan that gates WhatsApp, Freddy AI, and live translation behind $79 per agent Enterprise is not really $15 per agent. Do the math on the plan you will actually use, not the plan you first look at.
Once those two factors are priced honestly, the 10-agent, 3,000-AI-conversations-per-month benchmark works out to roughly $21,000 annually on Zendesk, $9,000 on Freshdesk, and under $2,000 on Deskwoot.
Common customer support mistakes small businesses make
Over-buying. Enterprise platforms are tempting because they are well-marketed. For a team of 8, Zendesk Enterprise is massive overkill. Pay for the features you will use, not the ones the sales deck showed.
Under-buying AI. Refusing to deploy AI in 2026 because it feels untested costs you 30 to 60 percent agent time on repeat questions. Grounded AI chatbots handle shipping, returns, and account questions reliably. Teams without AI are paying humans to do robot work.
Not connecting the CRM. A support agent who cannot see a customer’s past purchases, open tickets, or subscription status answers slower and less accurately. CRM integration is not a nice-to-have in 2026.
Ignoring mobile. Small business owners live on their phones. A support platform without a real mobile app loses 20 to 40 percent of practical value once the team scales past two.
Delaying the move from shared inbox. The cheapest platform to implement is the one you put in before you absolutely need it. Every month on the shared inbox past the breaking point is lost CSAT, lost retention, and lost learning.
FAQ: customer support software for small business
Do I need customer support software if I only have three employees? Probably not yet. A shared inbox works fine at that scale. Plan the move before you hit five and definitely before you hit ten.
Is there a free customer support software for small business? Deskwoot has a free plan for one agent with core features. Tawk.to is free with ads. Freshdesk has a limited free tier. For teams under five, these cover most use cases.
Which platform integrates best with Outlook? Most modern platforms forward emails from Outlook cleanly. For tighter integration (calendar, contacts, tasks), look for native Microsoft 365 or Google Workspace integrations. Cross-platform data sync tools can bridge gaps.
How much should a small business budget for customer support software? Budget $5 to $15 per agent per month as the baseline. Add $50 to $150 per month for AI usage if your volume is moderate. Total monthly spend for a 5-agent team: typically $100 to $250.
Can I switch platforms later? Yes, most modern customer support software includes one-click migration tools from the main competitors. The harder switch is from an ad-hoc shared inbox because the history lives in email folders, not a structured database.