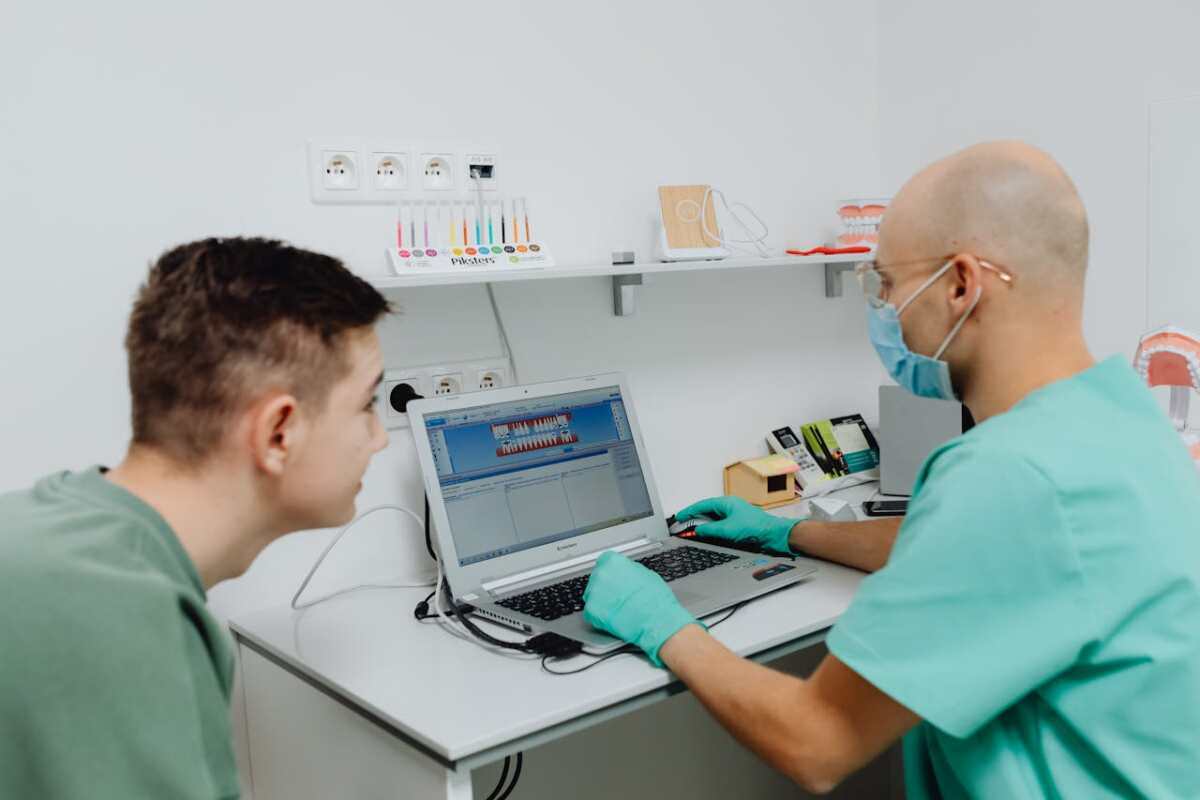
Healthcare software is no longer judged solely by usability or speed to market. In today’s regulatory landscape, compliance is the foundation of trust – especially when dealing with sensitive patient data and system interoperability.
For healthcare providers, payers, and healthtech startups, working with a healthcare software development company that understands HIPAA and HL7 requirements is critical. Non-compliance can result in severe financial penalties, operational disruption, and long-term reputational damage.
Below are the essential features and capabilities every compliant healthcare software solution should deliver – and what decision-makers should look for when choosing a development partner.
1. Robust Data Security & Access Controls (HIPAA Core Requirement)
HIPAA compliance begins with protecting electronic Protected Health Information (ePHI). Any healthcare software must include security features that prevent unauthorized access, breaches, or data leakage.
Key requirements include:
End-to-end encryption (data at rest and in transit)
Role-based access control (RBAC) to limit user permissions
Multi-factor authentication (MFA) for sensitive operations
Secure session management and timeout policies
Without these safeguards, even well-designed healthcare applications can expose organizations to compliance violations.
2. Comprehensive Audit Trails & Activity Logging
HIPAA mandates that organizations maintain detailed records of how patient data is accessed and modified. From a software perspective, this means building immutable audit trails into the system architecture.
A compliant platform should:
Log all user actions involving patient data
Record timestamps, user IDs, and affected records
Allow administrators to generate compliance-ready audit reports
Auditability not only supports HIPAA compliance – it also simplifies internal investigations and regulatory reviews.
3. HL7-Compliant Interoperability & Data Exchange
Modern healthcare systems rarely operate in isolation. Interoperability between EHRs, labs, pharmacies, and third-party platforms is essential – and that’s where HL7 standards come in.
HL7-compliant healthcare systems enable:
Structured clinical data exchange across platforms
Reduced data duplication and manual entry
Improved care coordination and patient outcomes
A healthcare software development company must be experienced in implementing HL7 v2, HL7 v3, or FHIR standards depending on the system’s scope and integration needs.
4. Secure EHR Integration & Customization
Electronic Health Records remain the backbone of digital healthcare operations. Whether building a new system or integrating with an existing one, compliance must be embedded at every layer.
HL7/FHIR-based interoperability with external systems
Scalability for future regulatory and technical changes
EHR platforms that lack compliance-ready architecture often struggle to adapt as regulations evolve.
5. Data Backup, Recovery & Business Continuity Planning
HIPAA requires covered entities to ensure data availability – even during system failures or cyber incidents. That makes disaster recovery and backup strategies a must-have feature, not an afterthought.
Best practices include:
Automated, encrypted data backups
Redundant storage across secure locations
Documented recovery time objectives (RTOs)
Regular disaster recovery testing
Reliable recovery mechanisms protect both patient safety and regulatory standing.
6. Ongoing Compliance Monitoring & Documentation
HIPAA and HL7 are not “set-and-forget” standards. Software systems must adapt to regulatory updates, evolving security threats, and operational changes.
A capable development partner will:
Support compliance audits and documentation
Implement security updates and patches
Provide guidance on regulatory best practices
Align development processes with healthcare compliance frameworks
This long-term compliance mindset separates experienced healthcare vendors from general software providers.
Choosing the Right Healthcare Software Development Partner
Building compliant healthcare software requires more than technical expertise – it demands a deep understanding of healthcare regulations, workflows, and interoperability standards.
Healthcare-focused case studies and domain expertise
Transparent compliance processes and documentation
Companies like Saigon Technology demonstrate how specialized healthcare development expertise can help organizations build secure, interoperable, and regulation-ready digital solutions.
Final Thoughts
HIPAA and HL7 compliance are no longer optional – they are prerequisites for trust in digital healthcare. By prioritizing security, interoperability, auditability, and long-term compliance support, healthcare organizations can reduce risk while delivering better patient outcomes.
The right healthcare software development company doesn’t just build applications – it builds confidence, compliance, and scalability into every line of code.
Key Features of HIPAA and HL7 Compliant Healthcare Software was last modified: April 8th, 2026 by Alven Smith
Choosing a MySQL connector for .NET is not just a cost decision. It affects security architecture, performance behavior, ORM integration, and long-term maintainability.
Free connectors solve runtime connectivity. Commercial connectors aim to solve connectivity plus enterprise constraints: secure transport layers, tooling integration, and governance requirements.
This comparison examines:
Free tools
MySQL Connector/NET (Oracle)
MySqlConnector
Commercial tools
Devart dotConnect for MySQL
Progress DataDirect Connect for ADO.NET
The objective is not to promote pricing tiers—but to clarify where commercial tooling delivers structural advantages.
Free MySQL Connectors
Free connectors are sufficient for many projects. They provide stable ADO.NET access and support standard SSL/TLS encryption.
However, their scope typically ends at runtime functionality.
MySQL Connector/NET (Oracle)
MySQL Connector/NET is the official managed provider from Oracle and serves as the baseline implementation for MySQL in .NET.
It supports:
Standard ADO.NET interfaces
SSL/TLS encryption
Compatibility with MySQL Server releases
Basic ORM integration
Strengths:
Official vendor distribution
Predictable compatibility
No licensing cost
Limitations:
No built-in SSH connectivity
No HTTP tunneling
Limited development tooling
Focused primarily on core connectivity
It works well when infrastructure allows direct DB access and extended tooling is not required.
MySqlConnector
MySqlConnector is a modern, async-first open-source driver optimized for performance and concurrency.
It emphasizes:
True asynchronous I/O
Efficient connection pooling
Broad compatibility with MySQL and MariaDB
Lightweight NuGet-based deployment
Strengths:
Excellent performance in ASP.NET Core APIs
Clean modern architecture
Strong behavior under concurrency
Limitations:
No built-in secure tunneling layers
No design-time Visual Studio tooling
Community support model
It is often the preferred choice for performance-focused, cloud-native services.
Commercial MySQL Connectors
Commercial connectors expand the scope from “connect and query” to “operate securely at scale.”
They address:
Network restrictions
Secure transport requirements
Enterprise governance
Structured vendor accountability
Integrated development workflow
Devart dotConnect for MySQL
dotConnect for MySQL is a commercial ADO.NET provider that extends beyond baseline connectivity by integrating secure transport options, ORM providers, and Visual Studio tooling into a unified ecosystem.
What makes it stand out technically:
1. Network Flexibility Built Into the Driver
Unlike free connectors, dotConnect supports:
SSL encryption
Built-in SSH connections
HTTP tunneling
This means secure connectivity can be configured directly at the provider level without relying on external SSH tunnel services or infrastructure modifications.
In restricted corporate environments, this capability alone can reduce deployment friction significantly.
2. Integrated ORM Ecosystem
dotConnect provides:
Dedicated EF Core provider
EF6 provider
Enhanced MySQL-specific feature handling
Bulk and batching capabilities
This is not just runtime compatibility—it is structured ORM integration with vendor-backed updates.
For teams that rely heavily on Entity Framework, this reduces edge-case behavior and version drift risks.
3. Visual Studio Integration and Developer Workflow
dotConnect includes:
Design-time components
DataSet designers
Extended configuration tools
Performance-oriented utilities
Free connectors typically operate only at runtime. dotConnect improves the development workflow itself, which impacts productivity across larger teams.
4. Enterprise Support and Accountability
Commercial licensing provides:
Structured vendor support
Defined release cadence
Predictable maintenance
Risk mitigation for production systems
In regulated or high-availability environments, accountability becomes part of the technical evaluation.
Where dotConnect Justifies Attention
dotConnect is not positioned merely as a paid alternative. It targets scenarios where:
Direct DB ports are restricted
SSH or proxy routing is required
EF Core integration must be stable and vendor-supported
Visual Studio tooling is part of daily workflow
Production systems require formal support channels
In such environments, the additional feature surface is not optional—it solves real deployment constraints.
Progress DataDirect Connect for ADO.NET
Progress DataDirect focuses on enterprise-standardized, managed connectivity across multiple database platforms.
Its differentiators:
Fully managed wire-protocol provider
Enterprise-grade encryption
Cross-database standardization strategy
Vendor-backed SLAs
DataDirect is typically chosen when an organization standardizes one connector vendor across Oracle, SQL Server, PostgreSQL, and MySQL.
It prioritizes governance over developer tooling richness.
Direct Comparison: Free vs Commercial
Security & Network Capabilities
Feature
Free Connectors
dotConnect
DataDirect
SSL/TLS
Yes
Yes
Yes
Built-in SSH
No
Yes
No
HTTP Tunneling
No
Yes
No
Enterprise Encryption Controls
Basic
Advanced
Advanced
If your infrastructure allows direct access, free tools are sufficient. If network routing or firewall restrictions are common, dotConnect offers a technically cleaner solution.
Performance & Concurrency
Scenario
Best Fit
High-load API services
MySqlConnector
Balanced enterprise apps
dotConnect
Standard CRUD apps
Connector/NET
Governance-focused environments
DataDirect
Performance differences often appear under concurrency stress. However, performance alone is rarely the only deciding factor in enterprise systems.
Tooling & Workflow
Capability
Free
dotConnect
DataDirect
EF Core Provider
Yes
Dedicated
Yes
Visual Studio Design Tools
Minimal
Strong
Limited
Bulk Utilities
Basic
Extended
Enterprise-level
Vendor SLA
No
Yes
Yes
dotConnect provides the strongest development workflow integration among the compared tools.
When Free Tools Are Enough
Free connectors are sufficient when:
Infrastructure is simple
Direct database connectivity is allowed
Advanced tunneling is not required
Community support is acceptable
The team prefers lightweight runtime-only solutions
For startups or API-driven platforms, MySqlConnector is often a strong choice.
When Commercial Tools Become Strategic
Commercial connectors become strategic when:
Network constraints exist
Secure transport flexibility is required
Enterprise governance applies
Vendor accountability matters
ORM reliability must be predictable
Development workflow efficiency impacts team velocity
In those cases, dotConnect for MySQL offers a broader architectural surface—not just a paid version of the same thing.
Summary
Free MySQL connectors such as MySQL Connector/NET and MySqlConnector provide reliable baseline connectivity for .NET applications. They are well suited for straightforward architectures, API-driven systems, and environments where direct database access is allowed and infrastructure is uncomplicated. MySqlConnector, in particular, stands out in high-concurrency and async-heavy workloads.
Commercial connectors expand the scope beyond runtime access. They address secure transport flexibility, enterprise governance, structured vendor support, and deeper integration into development workflows. The right choice depends on architectural priorities.
Free vs Commercial MySQL Connectors for .NET Developers was last modified: March 30th, 2026 by Evelina Brown
The buzz surrounding decentralized data management has finally matured into something far more boring – and far more useful. It’s no longer about speculation; it’s about fixing the broken trust in enterprise systems. Today, organizations treat distributed ledgers as a blunt instrument to carve out fraud and force transparency into their operations. But here’s the reality: choosing a technical partner in this space is a high-stakes gamble.
You need a crew that understands the friction between raw cryptography and the heavy hand of global regulators. A single oversight in a smart contract doesn’t just cause a bug – it causes an extinction-level event for your assets. When vetting blockchain development companies, the smart play is to look for those who have navigated the minefield of actual banking licenses. Here is a candid look at five firms currently delivering high-integrity digital products.
S-PRO
Founded: 2014
Presence: Switzerland, USA, Ukraine, Poland
Rate: $25 – $49/hr
Key Work: AMINA (Swiss Digital Bank), CoinMENA, TSO Chinese
S-PRO acts more like a specialized engineering lab than a traditional outsource shop. With over 300 projects under their belt, they focus on the structural “bones” of a system before they even think about the UI. Their engineers are obsessed with custom blockchain architecture that can actually scale without choking under transaction volume. Their work for a Swiss-regulated digital asset bank is a perfect example—they had to build within the tightest financial constraints on the planet. They also handled the launch of CoinMENA, which required a deep dive into Sharia-compliant logic. It’s this ability to translate complex legal needs into clean code that makes S-PRO a top-tier choice for fintech.
LeewayHertz
Founded: 2007
Presence: USA, India
Rate: $50 – $99/hr
Key Work: Logistics tracking, Healthcare data silos
LeewayHertz has planted its flag in the world of permissioned ledgers. While the crypto world loves public chains, LeewayHertz understands that a Fortune 500 company needs a closed ecosystem where they control who sees what. They do a lot of heavy lifting with Hyperledger Fabric to solve supply chain headaches. Their platforms allow global shipping firms to track cargo in real-time, creating a paper trail that simply cannot be faked. It’s practical, rugged tech that cuts down on the typical “hidden costs” of international trade.
PixelPlex
Founded: 2013
Presence: USA, Switzerland, Poland
Rate: $50 – $99/hr
Key Work: Real-world asset tokenization, DEX development
PixelPlex leans heavily into the security side of the house. They have a reputation for being the “paranoid” developers—which is exactly what you want when millions of dollars are on the line. Their security layer stress-tests smart contracts for every known exploit before a single line of code goes live on a mainnet. They’ve pioneered work in tokenizing physical assets like real estate, helping investment trusts break down massive properties into tradeable, fractional shares without running afoul of local securities laws.
SoluLab
Founded: 2014
Presence: USA, India, Australia
Rate: $25 – $49/hr
Key Work: NFT marketplaces, Non-custodial wallets
SoluLab is built for the “move fast” crowd, but they don’t sacrifice the underlying math to do it. They are incredibly versatile, switching between consensus protocols based on whether a client needs lightning speed or maximum decentralization. Lately, they’ve been the go-to for non-custodial wallet solutions, focusing on making the Web3 experience feel less like a science experiment and more like a standard app. For brands looking to dip their toes into decentralized loyalty programs or digital collectibles, they are a solid, agile partner.
ScienceSoft has been around since 1989, so they’re not new to this. They focus on the hard part — moving data from outdated ERP systems into something that actually works. It’s risky, but their cybersecurity background helps keep everything stable. They’ve helped banks turn slow, multi-day international transfers into instant ones, while still meeting standards like HIPAA and PCI DSS.
Practical Realities of Vendor Selection
Shipping a secure digital product isn’t about finding the cheapest hourly rate; it’s about avoiding a catastrophic security failure. You have to look past the marketing decks and verify their history with high-traffic environments. In this industry, security flaws are usually permanent and incredibly public. Prioritizing a team that understands both the code and the compliance landscape isn’t just a “nice to have”—it’s a survival requirement.
Top 5 Blockchain Development Companies for Secure Digital Products was last modified: March 26th, 2026 by Oleksandr Kryvotsiuk
California has more software development firms per square mile than almost anywhere else. This sounds like a buyer’s advantage, until you’re the one doing the research.
Most firms target the same keywords, display Clutch badges, and pitch an agile process. What rarely surfaces on their websites is engineer tenure, architecture decision history, or what happens when a project hits a wall at month four. Finding this out means working through dozens of sources. This article does it for you.
How to Evaluate a California Software Development Company Beyond Case Studies
Case studies are written when projects succeed, curated by marketing teams, and rarely mention the friction, delays, or renegotiations along the way. They’re a useful starting point, but not enough for a high-stakes vendor decision.
Here is what enterprise buyers should examine instead.
1. Delivery Maturity
Ask specifically about how they have handled scope changes, technical blockers, and unexpected dependencies mid-project.
Mature delivery organizations have documented processes for sprint planning, risk escalation, and post-mortems. They can tell you how they communicate when something goes wrong.
2. Retention of Senior Engineers
High turnover at the senior level is a signal of internal problems. It may be compensation, culture, or organizational dysfunction, and that will definitely surface in your project. Ask for the average tenure of the engineers who would be assigned to your account. Ask whether the company uses salaried staff or contract-based workers.
3. Product Ownership Capability
Ask the firm to walk you through a time they disagreed with a client requirement. How did they raise it? What happened? The answer will tell you a great deal about whether they function as an order-taker or as a genuine engineering partner.
Key question to ask:“Tell me about a time your team pushed back on a client’s technical requirement. What was the situation, and how did you handle it?”
4. Architecture Decision Quality
The quality of a firm’s architecture decisions is among the most consequential yet hardest to assess from the outside. Try to:
Speak with the lead architect or technical principal on recent projects.
Get a description of a trade-off decision they made and why.
Ask how they balance build speed and long-term maintainability.
Pay attention to how they handle ambiguity.
5. Executive Communication
Look for firms that assign a senior point of contact who participates in project governance. Ask how often executive-level check-ins are structured and what format they take. Ask how they have handled situations where a project was falling behind, and the client needed to be informed.
List of Top Software Development Companies in California
Each profile includes what they are good at, how much they charge, and their Clutch rating. Start with the ones that match your industry or delivery needs.
Company
Core Expertise
Pricing ($/hr)
Min. Project Size
Clutch Rating
Baytech Consulting
Custom software, AI integration, CRM, cloud/DevOps, enterprise apps
$100–$149
$25K+
5 / 5
Utility
Custom mobile app development, web platforms, AI-powered solutions, UX/UI strategy
AI/ML, web/mobile, data engineering, DevOps, staff augmentation
$25–$49
$10K+
4.9 / 5
WebcentriQ
Custom software, web/mobile, UX/UI, CRM
$50–$99
$10K+
4.9 / 5
Baytech Consulting
Onshore enterprise software partner | Irvine, California
Baytech Consulting is one of the best software development companies in California for enterprise clients who need a single, accountable onshore team. With 20+ years of operation, 120+ completed projects, and a 5/5 Clutch rating, the firm works with clients ranging from SMBs to Fortune 500. Core verticals include healthcare, finance, real estate, manufacturing, and legal, where regulatory requirements, data sensitivity, and system uptime make vendor continuity a priority.
Scope, cost, and timeline are fixed before development begins, which reduces the budget unpredictability common in time-and-materials contracts. Clients have direct access to engineers throughout the project, and progress is reviewed through sprint demos at each stage rather than consolidated at delivery. TDD and CI are standard practices that affect both defect rates during development and maintainability after handoff.
Notable capability: 20% monthly revenue growth for Allied American Health; $3M+ unlocked for CashCall Inc. via a custom lead-routing CRM; a first-to-market lead delivery system for New American Funding. Baytech also holds a Clutch Fall 2024 Global Award in software development and app modernization, and offers a dedicated Project Rescue service (an engagement path for taking over failed or stalled builds from other vendors, structured as an explicit service rather than an ad hoc arrangement).
Core services: Mobile app development, AI development, enterprise app modernization.
Best fit: Mid-market to Fortune 500 companies in regulated industries needing full onshore accountability, fixed-scope contracts, and long-term engineering continuity or a reliable rescue path when a previous vendor has stalled.
Utility
Digital product agency for consumer-centric solutions | Los Angeles, California
Utility is a digital product agency founded in 2013, with 100+ team members, 150+ delivered projects, and a client list that spans growth-stage startups and global enterprise brands, such as Airbnb, Coca-Cola, Samsung, the NBA, and Forbes. Core verticals include media, entertainment, sports, consumer tech, and real estate. Services cover custom mobile app development, web platform development, AI-powered solutions, and UX/UI strategy, with native iOS/Android and cross-platform builds both in scope.
What distinguishes Utility’s model is a consistent pattern of being brought in as the primary digital partner for high-visibility, high-complexity launches: events, consumer platforms, and products where failure is public. Engagements are led by senior product strategists and UX/UI designers working alongside engineers from kickoff.
Notable capability: Utility served as the digital arm for the Airbnb Open global conference for three consecutive years, building web and mobile platforms covering registration, itinerary planning, dynamic ticketing, and on-site engagement tools for 20,000+ attendees from 100+ countries; built all mobile and web experiences for the NBA World Championship tournament, covering team registration, ticket sales, and real-time brackets; developed the full mobile app and Smart Lockbox integration for TOOR, a property-access startup that appeared on Shark Tank; and built Snack-app, an AI-powered sports highlights platform available on iOS and Android.
Core services: Custom mobile app development (iOS, Android, cross-platform), web platform development, AI-powered solutions, UX/UI strategy and design.
Best fit: Consumer-facing startups and enterprise brands in media, sports, entertainment, and real estate that need a single team to own the full product on high-stakes launches where execution quality is non-negotiable.
Baunfire
Best for B2B Tech Brand Websites in Silicon Valley | San Jose, CA
Baunfire is a digital agency founded in 2001, with 20+ years of operation and a 5/5 Clutch rating. The firm partners with leading global brands, venture capital firms, and funded startups. Their client list includes Google, Nike, Sapphire Ventures, and Norwest Venture Partners. Its focus is narrow and consistent: high-performance B2B marketing websites for established technology brands, growth-stage SaaS companies, and venture-backed startups that need their digital presence to reflect a repositioned or maturing brand.
Engagements combine brand strategy, UX, and front-end engineering into a single team. This matters for post-rebrand website rebuilds and enterprise CMS migrations, where misalignment between brand, content architecture, and technical execution is a common failure point. Baunfire is also a 2023 Clutch Global Award winner and has received recognition from AWWARDS and the American Advertising Federation of Silicon Valley.
Notable capability: A website rebuild for Omron Robotics resulted in doubled website visits and significant increases in engagement and organic traffic; a full redesign and launch for Amplitude, a leading digital analytics platform, focused on modernizing visual design and improving content accessibility; a corporate website for Norwest Venture Partners built to elevate digital presence and user engagement; a digital brand and web partnership with SymphonyAI covering AI applications across retail, financial services, and manufacturing.
Core services: B2B marketing website design and development, UX/UI design, front-end web development, brand and digital strategy, digital marketing and SEO, custom CMS implementation.
Best fit: Growth-stage and enterprise B2B technology companies needing a single team to translate a brand repositioning or post-rebrand strategy into a high-performing marketing website.
Bluelight
SOC 2-compliant delivery with Latin American senior talent | Sacramento, CA
Founded in 2016, Bluelight operates as a nearshore software partner with engineering teams across Latin America and client-facing management on the U.S. side. A rating is consistent across Clutch, Glassdoor, and GoodFirms. Industry coverage spans financial services, government, hospitality, information technology, and supply chain, with a client list that includes Tyler Technologies and Fanatics at the enterprise end.
What separates Bluelight from talent marketplaces is the depth of vetting: coding challenge recordings, interview videos, and detailed technical evaluations are provided before any engineer is placed, removing the screening burden from the client side. DevOps and CI/CD architecture are where the firm’s engineering culture is most visible. SOC 2 compliance is a structured delivery component rather than an optional add-on, which matters for regulated-industry procurement.
Notable capability: A 50% faster documentation process at Sunrise Manufacturing following platform development by Bluelight; a 22% improvement in project delivery time for Tyler Technologies after augmenting their team with Bluelight’s DevOps, QA, project management, and machine learning engineers; a legacy Filemaker and Joomla system replaced with a single custom CRM for a travel agency, delivered on schedule; a healthcare client’s proof of concept converted into a production-ready product within a defined go-to-market timeline. Particular depth in hospitality CRM builds and government legacy system modernization.
Core services: Custom software development, staff augmentation, dedicated development teams, DevOps and cloud services, QA and test automation, SOC 2 compliance support, data engineering, and custom AI solutions.
Best fit: Startups and enterprises that need nearshore engineering capacity with U.S. time zone alignment, SOC 2-compliant delivery, and strong DevOps culture.
Azumo
Nearshore/onshore hybrid model with 3.2+ year average client partnerships | San Francisco, CA
9 years in operation, 300+ completed projects, 100+ enterprise clients globally, and a 4.9/5 Clutch rating; Azumo’s track record is consistent. The firm has delivered AI development services since 2016 for clients including Meta, Discovery Channel, Zynga, Omnicom, and Stovell AI across fintech, healthcare, media, gaming, and enterprise tech. Engineering teams operate from Latin America in U.S. time zones; project management and client oversight sit on the U.S. side. The average client relationship length of 3.2+ years is the metric that most distinguishes Azumo from typical nearshore providers, where churn after first delivery is common.
AI and ML are genuine practice areas. For LLM-based projects, the team evaluates GPT, Claude, LLaMA, and Mistral against accuracy and cost requirements before committing to an architecture. SOC 2 certification covers all deliverables relevant to regulated-industry procurement.
Notable capability: Generative AI enterprise search for Meta improving procurement team search precision; Big Run Studios gained near-real-time reporting across their live games portfolio via a full data lake on Amazon S3 and Snowflake, replacing limited Firebase aggregate data; a government-facing client had its legacy system rebuilt across four phases, culminating in an LLM-powered briefing generation tool; a venture-backed women’s health platform built and scaled as a multi-year development partnership.
Core services: AI/ML development, custom web and mobile applications, data engineering, DevOps and cloud migration, staff augmentation.
Best fit: Startups and enterprises in fintech, healthcare, media, or gaming that need AI-powered product development or engineering team augmentation with nearshore cost efficiency, U.S. time zone alignment, and a partner capable of staying involved long after the initial build.
WebcentriQ
AI and software transformation partner with proactive product ownership | San Diego, CA
Led by a CEO with a PhD in AI and a background at Microsoft, WebcentriQ is a San Diego-based software development firm founded in 2017. Healthcare, fintech, e-commerce, and marketing make up the core verticals. The firm operates as a full-stack development partner, covering custom software, web and mobile development, UX/UI design, and CRM implementation from a single team.
What reviewers consistently note is an approach that goes beyond task execution: WebcentriQ is recognized for proactively identifying and solving problems before they escalate. Also, clients express satisfaction with the team’s approach to establishing clear expectations.
Notable capability: Full-stack development for Dwelzi, a co-living marketplace platform, covering user onboarding, digital license agreements, background checks, Stripe payment integration, automated agreement generation, and smart home connectivity; a healthcare product built from scratch on Node.js, React, and native iOS that launched on the App Store and reached 350+ active users; a global technology and education platform rebuilt for stability, resulting in measurable improvements to uptime and page load speed.
Core services: Custom software development, web and mobile application development, UX/UI design, CRM consulting, and systems integration.
Best fit: SMBs, mid-market companies, and startups in healthcare, fintech, or real estate that need a technically rigorous partner to own the product long-term.
What Separates a Vendor from a Long-Term Technology Partner
Once you define your growth plan and shortlist the California software companies that fit your project, the next step is to understand which one can stay effective as priorities shift and technical complexity grows. A reliable long-term partner usually shows a few consistent patterns.
Long-term partners communicate problems early. They surface risk as it develops and bring solutions alongside the bad news.
They maintain institutional knowledge. Senior engineer retention, documentation practices, and structured onboarding mean that your project history does not evaporate when someone rolls off the account.
They push back. Partners with genuine product ownership capability will challenge requirements, flag downstream consequences, and advocate for technical decisions that serve the long-term product.
They plan for your independence. The best partners build toward clear handoffs. Clean codebases, thorough documentation, and structured offboarding processes are signs of a firm that is confident in its value.
Final Thoughts
The California software development market is mature, competitive, and full of capable firms. The difficulty is a shortage of the right framework for evaluating them.
The listed companies represent a range of delivery models, pricing points, and specializations. But the decision comes down to fit: technical alignment, communication style, engagement model, and the degree to which the firm’s operating philosophy matches your organization’s.
The framework and the questions listed are created to help you make that determination with precision. Take the time to evaluate carefully.
Best Software Development Companies in California Listed was last modified: June 15th, 2026 by Colleen Borator
Logistics software development services enable companies to design and implement digital platforms that improve visibility, automate operations, and optimize complex supply chains. As global trade accelerates and customer expectations for fast, reliable delivery increase, businesses can no longer rely on manual coordination or fragmented systems to manage logistics processes.
Modern logistics networks operate across multiple layers: suppliers, warehouses, carriers, customs, distribution centers, and last-mile delivery providers. Each layer generates large volumes of operational data that must be processed in real time. Without effective digital tools, organizations struggle to coordinate shipments, control costs, and maintain transparency across the entire chain.
This is why many companies are investing in custom logistics software tailored to their specific operational models. Unlike generic platforms, purpose-built logistics systems align with internal workflows, integrate with existing infrastructure, and adapt to the scale and complexity of the organization.
Why Logistics Software Is Becoming Mission-Critical
Supply chains today are far more dynamic than they were even a decade ago. Businesses must respond quickly to fluctuating demand, geopolitical disruptions, fuel price changes, and evolving regulatory requirements.
Digital logistics systems address these challenges by transforming disconnected operational processes into coordinated digital workflows. Through centralized platforms, companies can monitor shipments in real time, automate routing decisions, and predict delays before they impact customers.
The benefits of modern logistics software include:
Real-time visibility across transportation and inventory flows
Operational automation that reduces manual coordination
Predictive analytics to anticipate disruptions
Improved resource utilization for vehicles, warehouses, and personnel
Enhanced customer experience through accurate tracking and communication
When implemented effectively, logistics technology becomes the operational backbone that connects planning, execution, and analysis across the supply chain.
Core Types of Logistics Software
Logistics software development typically focuses on several critical system categories that support different operational layers.
Transportation Management Systems (TMS) TMS platforms help companies plan, execute, and optimize the movement of goods. These systems automate route planning, carrier selection, freight cost calculations, and shipment tracking.
A well-designed TMS reduces transportation expenses while improving delivery reliability. Advanced solutions can also incorporate real-time traffic data, fuel price monitoring, and predictive routing algorithms.
Warehouse Management Systems (WMS) Warehouses represent one of the most complex nodes within logistics operations. WMS platforms coordinate inventory storage, order picking, packing, and dispatching.
By integrating barcode scanning, IoT sensors, and automated picking systems, modern WMS solutions can significantly increase warehouse throughput while minimizing human error.
Fleet Management Platforms Fleet software helps logistics companies monitor vehicles, drivers, fuel consumption, and maintenance schedules. GPS tracking and telematics enable real-time monitoring of vehicle locations and driving behavior.
These platforms improve operational efficiency while helping organizations maintain compliance with safety regulations.
Last-Mile Delivery Systems With e-commerce growth, the final stage of delivery has become one of the most challenging aspects of logistics. Last-mile platforms optimize delivery routes, coordinate drivers, and provide customers with real-time updates.
Features often include route optimization algorithms, driver mobile apps, and automated proof-of-delivery systems.
Emerging Technologies Transforming Logistics
Advanced technologies are rapidly redefining how logistics platforms are designed and implemented.
Artificial Intelligence and Machine Learning
AI models can analyze historical logistics data to forecast demand patterns, identify potential bottlenecks, and recommend optimal transportation strategies. Machine learning algorithms continuously improve routing efficiency and warehouse operations.
Internet of Things (IoT)
IoT devices embedded in vehicles, containers, and warehouses generate continuous streams of operational data. Temperature sensors, GPS trackers, and equipment monitors enable real-time tracking of goods and environmental conditions.
This technology is especially valuable for industries such as pharmaceuticals and food logistics, where product integrity must be carefully maintained.
Blockchain for Supply Chain Transparency
Blockchain systems can create tamper-proof records of shipments and transactions. This improves traceability, enhances trust among supply chain participants, and simplifies regulatory compliance.
Although still emerging, blockchain applications are gaining attention in industries that require secure documentation and provenance tracking.
Cloud-Based Infrastructure
Cloud platforms allow logistics companies to scale digital systems without investing in expensive on-premise infrastructure. Cloud-native logistics solutions support distributed teams, real-time analytics, and integration with partner systems.
Custom Development vs. Off-the-Shelf Platforms
Many organizations initially adopt standard logistics software products. While these platforms provide basic functionality, they often struggle to support unique operational workflows or integrate with legacy systems.
Custom logistics software development addresses these limitations. Tailored solutions allow businesses to:
Build systems around existing logistics processes
Integrate with ERP, CRM, and external partner platforms
Implement specialized analytics and reporting tools
Adapt quickly to evolving operational requirements
For companies operating complex supply chains or specialized logistics services, custom platforms often deliver greater long-term value.
Implementation Considerations
Successful logistics software development requires careful planning and collaboration between technology teams and logistics professionals.
Key factors include:
Integration architecture Logistics platforms must communicate seamlessly with warehouse equipment, carrier systems, financial platforms, and customer portals.
Data quality and governance Accurate logistics analytics depend on consistent and well-structured operational data.
Scalability As companies expand into new markets or add distribution centers, logistics systems must scale accordingly.
User experience Warehouse staff, drivers, planners, and managers interact with logistics platforms daily. Intuitive interfaces significantly improve productivity and adoption.
The Strategic Value of Logistics Technology
Digital logistics platforms no longer serve merely as operational tools. They are increasingly strategic assets that influence customer satisfaction, operational efficiency, and competitive positioning.
Organizations that invest in modern logistics technology can respond more quickly to disruptions, optimize transportation costs, and deliver better customer experiences. As global supply chains become more complex, the importance of flexible and scalable logistics software will continue to grow.
Technology partners play a crucial role in designing these systems. Experienced providers combine deep engineering capabilities with an understanding of supply chain processes to build platforms that support real-world logistics operations. For example, Andersen logistics software development services focus on creating scalable, data-driven solutions that help companies modernize transportation management, warehouse operations, and supply chain analytics in an increasingly digital logistics environment.
Logistics Software Development Services: Building the Digital Backbone of Modern Supply Chains was last modified: March 16th, 2026 by Viktoryia Tsyunel
In the world of professional productivity, we often discuss the synchronization of data, the optimization of workflows, and the importance of high-fidelity communication. However, an often-overlooked component of a leader’s “interface” is their visual brand. In 2026, professional grooming is no longer viewed as a matter of vanity; it is a system that requires regular “patching” and maintenance to ensure the message you send is consistent with your expertise.
Just as a software developer must manage technical debt to prevent a system from slowing down, a professional must manage “aesthetic debt”—the gradual degradation of their visual presentation due to environmental stressors. For those with color-treated hair, the most common system error is “brassiness,” a shift in tonal frequency that can make a polished executive look fatigued or unkempt. Solving this requires more than a random product; it requires an understanding of color-theory logic.
The Color Wheel Algorithm: Understanding Complementary Tones
To troubleshoot hair color effectively, one must understand the “Logic of Opposites.” Color theory operates on a fixed algorithm: colors that sit directly opposite each other on the color wheel will neutralize one another when combined. In the context of hair, this is known as “Tonal Cancellation.”
When hair is lightened, the natural pigments—pheomelanin and eumelanin—are stripped away, often revealing underlying warm tones. For blondes, this usually manifests as a yellow or gold “glitch.” For brunettes or those with darker hair, the underlying warmth appears as orange or red. To restore the “factory settings” of your hair color, you must apply a pigment that sits on the opposite side of the spectrum.
Troubleshooting Brassy Tones: A Logical Framework
The primary confusion in color maintenance stems from selecting the wrong “patch” for the specific tonal error. Using the wrong pigment is like trying to run an iOS update on an Android device; it simply won’t resolve the issue.
The decision-making process is binary:
If the “glitch” is yellow: Use violet-based pigments.
If the “glitch” is orange: Use blue-based pigments.
For a deeper dive into the technicalities of these pigments, having the tonal neutralization science explained can save hours of trial and error. Violet pigments are smaller and designed to counteract the pale yellow frequencies found in blonde, silver, or platinum hair. Conversely, blue pigments are more robust, designed to cut through the deeper, stubborn orange “noise” that plagues highlighted brunettes or those with “bronde” (brown-blonde) transitions. Understanding this distinction is the difference between a successful “system restore” and a wasted investment.
Synchronization: Aligning Your Routine with Your Schedule
The most productive professionals don’t wait for a system failure to take action; they build maintenance into their schedule. Color maintenance should be viewed as a “background process”—something that happens periodically to prevent the need for an emergency “reboot” (a costly, unscheduled trip to the salon).
Integrating a pigment-depositing cleanser into your routine once or twice a week acts as a “sync.” It maintains the integrity of the original color, extending the “uptime” of your salon service by several weeks. In terms of ROI, the 5-minute investment in the shower yields a significant return in saved time and maintained professional authority.
In 2026, the “hardware” we use to maintain ourselves is under scrutiny. Just as we prefer efficient, sustainable energy sources for our tech, we must look for sustainable chemistry in our grooming products. High-performance brands like Davines utilize B-Corp standards to ensure that the pigments used are not only effective but are delivered in a biodegradable, carbon-neutral package.
Choosing “Clean Chemistry” ensures that your personal maintenance doesn’t create negative externalities. For the modern leader, this alignment of personal ethics and professional appearance is a key component of an authentic brand identity.
Conclusion: High-Fidelity Personal Branding
Efficiency is the elimination of waste—waste of time, waste of money, and waste of energy. By applying a logical framework to your personal grooming, you eliminate the guesswork and ensure that your “interface” is always operating at peak performance.
Maintaining your hair’s tonal integrity isn’t just about color; it’s about the precision and attention to detail that defines your professional life. When your data is synced and your image is optimized, you are free to focus on what truly matters: leading your team and scaling your vision.
Optimizing Your Professional Image: The Technical Logic of Color Maintenance was last modified: March 10th, 2026 by Grind
There’s something off about how engineering works right now. Structural analysis and design software has come a long way. FEA solvers handle nonlinear dynamics, multiphysics, really demanding simulations. They’ve come a long way. But code checking in a lot of companies still runs on spreadsheets. That gap makes misreading results easier than it should be.
This piece looks at how automated code checking operates and what that shift means for calculation reliability.
The Problem with Traditional Post-Processing
You run your FEA model and convergence comes through. Good. Now you start pulling stresses, forces, and displacements out by hand. On serious structures like offshore platforms or high-rise buildings, the results pile up into gigabytes. But size isn’t the issue. What hurts is converting physical quantities (MPa, N, mm) into dimensionless utilization factors that standards demand. Running that by hand across thousands of elements is where mistakes creep in.
Exporting to Excel looks straightforward. It really isn’t.
Spot checking is the first trap. Engineers can’t check every finite element under every load combination. There’s simply no way. So you focus on areas where stress concentrations probably sit. But every now and then, and anyone who’s been through this knows what I mean, you miss local buckling somewhere that looked clean. Torsion combined with compression made that spot critical, and nothing told you to look there.
Then there’s the broken link with the model. Data in Excel is static, dead the moment you export it. Change geometry or boundary conditions, and your spreadsheet is instantly outdated. During iterative design people sometimes rebuild it and sometimes don’t. Decisions get made on stale numbers.
Auditability is the third issue. Hand a reviewer your custom script with nested macros four layers deep. Certification bodies like DNV, ABS, and RMRS want intermediate calculations now, proof that standard formulas were applied correctly. Your tangled macro setup doesn’t give them that.
The Mechanics of Automated Verification
Automated structural analysis and design software like SDC Verifier skip the export step entirely. They sit on the FEA solver database, pulling from the complete result set with nothing in between. The process splits into three stages: topology recognition, load processing, and code logic application.
Feature Recognition
FEA solvers are blind to what a structure actually is. A model is nodes connected to elements through a stiffness matrix. The solver has no idea that BEAM elements form a column or that SHELL elements make up a pressure vessel wall.
Recognition algorithms handle that. They cluster finite elements into engineering entities.
Take members. Collinear elements get merged into a single member for correct buckling length calculation. Standards like Eurocode 3 or AISC 360 tie load-bearing capacity to the slenderness of the entire member, not local stress in one element. If the grouping is wrong, the utilization ratio is meaningless.
Then panels and stiffeners. Shell fields between stiffeners get identified automatically for plate buckling checks under DNV or ABS standards. Panel dimensions (a x b), plate thickness, acting stresses, all extracted without anyone entering geometry by hand.
And welds. Element connection nodes get flagged for fatigue strength assessment. Simple in concept, easy to miss when doing it manually across hundreds of joints.
Managing Load Combinatorics
Superposition is where automation pays for itself. Industrial problems throw hundreds of load cases at you. SDC Verifier forms linear combinations after the solve, no rerunning needed. Then envelope methods scan every possible combination, thousands of them, pulling the worst case for each element. So even if peak stress on some bracket happens under an unlikely mix, say north wind plus empty tank plus seismic simultaneously, it gets flagged.
Without that you’re guessing which combinations govern.
Code Checks and Formula Calculations
At the core sits a library of digitized standards. Not a black box though. The formulas are visible, which matters more than you’d think. Check a beam against API 2A-WSD and you can follow exactly how axial force (f_a) and bending moments (f_b) get extracted from FEA results and substituted into interaction equations. Traceable from input to output.
Customization runs alongside that, and honestly it’s just as important. Engineers often need to modify standard formulas or build checks for internal company rules no published standard covers. The built-in formula editor with access to model variables makes that possible. For some firms this is the reason they adopt the system in the first place.
Engineering Interpretation and Applicability Limits
Here’s where the engineer’s role changes shape. The software runs millions of checks in minutes, so calculation speed is no longer the bottleneck. What remains is making sure inputs are right and outputs make physical sense. Get the boundary conditions wrong and the system won’t notice. It’ll produce clean, well-formatted, completely wrong results.
Stress singularity zones trip people up regularly. FEA produces points with theoretically infinite stress — concentrated loads, sharp re-entrant corners, that kind of geometry generates them reliably. Without proper configuration, this creates noise that buries real issues. An experienced engineer handles this by:
applying averaging filters to smooth out mathematical artifacts
marking singularity zones for exclusion (hot spot exclusion)
distinguishing between a mathematical artifact and an actual strength problem
Choice of calculation method stays human too. Switching between Elastic and Plastic checks is easy. But whether plastic deformations are acceptable in a specific structure is not a question software answers. That comes from the technical specification and from understanding how the structure behaves in service.
Documentation as Part of the Calculation Process
Reports in engineering consulting are legal documents. Not summaries, not appendices. Legal documents. Anyone who’s assembled one by hand knows the pain. Screenshots that go stale the moment geometry changes. Tables rebuilt from scratch after every iteration.
Automated software generate calculation protocols tied directly to the model. The model changes, the report updates. No confusion about which version of the geometry a screenshot came from.
For each critical element the report lays out context (element location in the 3D model), input data (forces and moments for the governing load combination), the process itself (standard formulas step by step with real numbers substituted in), and the verdict (safety factor and the code provision it references).
When the model changes, say a larger beam section or adjusted loading, the report regenerates automatically. Documentation prep time drops by 50 to 70 percent, and that freed-up time goes back to actual engineering work.
Software Selection Criteria
When selecting software, two criteria matter most:
Integration depth. External post-processors that require file conversion tend to lose attribute information along the way — component names, material properties, things you actually need. What works better is a solution embedded inside the pre/post-processor environment. SDC Verifier is an independent software that also offers native integration with Ansys Mechanical, Femap, and Simcenter 3D, giving direct access to the results database (RST, OP2) — no translation layer, no conversion artifacts.
Code coverage. If the software ships with current industry standards built in (ISO, EN, AISC, DNV, API, ASME) you start right away instead of building rule sets from scratch. Look at specialized checks too: fatigue, bolted connections, welded joints, hot spot extrapolation. These involve complex preliminary stress processing and they’re exactly where manual approaches fall apart fastest.
Conclusion
This shift isn’t coming. It’s already here. Code checking automation is happening now across construction and mechanical engineering. The move from manual “Excel engineering” to integrated verification means every structural element actually gets checked, and the usual data-transfer errors mostly drop out.
For engineering firms that translates to faster turnaround, yes. But also more design variants tested, better optimization, and something clients increasingly care about, which is auditable proof that the structure meets requirements. Safety regulations keep tightening. Deadlines keep compressing. Knowing how to use these tools stopped being a bonus a while ago. It’s just part of what structural engineering looks like now.
Automating Code Checking in Structural Analysis: Technical Breakdown and Implementation Methodology was last modified: March 6th, 2026 by Colleen Borator
Digital products today are expected to scale instantly – whether growth comes from marketing campaigns, seasonal spikes, or expansion into new markets. At the same time, infrastructure spending keeps rising, and many companies discover that growth brings technical strain along with revenue.
The real challenge isn’t scaling systems. It’s scaling them without losing stability or cost control. Teams that adopt structured DevOps services and solutions early usually get there faster because scalability, automation, and cost visibility are built into the operating model from day one.
When Growth Starts Creating Problems
Infrastructure rarely fails when systems are under low load. Issues usually appear the moment demand increases and platforms are pushed beyond their initial limits. What once worked reliably begins producing slowdowns, instability, or unexpected costs.
Three signals typically appear first:
Releases become slower as environments grow more complex
Costs increase faster than real usage
Failures happen during peak traffic
These symptoms indicate the same underlying issue: infrastructure was built quickly to launch, not intentionally to scale.
Why Mature Companies Treat Infrastructure as Strategy
Companies that scale successfully don’t treat infrastructure as a background system – they see it as part of their growth strategy. Instead of fixing problems after they appear, they build systems that can handle traffic spikes, bottlenecks, and cost pressure in advance. This makes releases more predictable, systems more stable, and expenses easier to control.
The Principles That Actually Reduce Scaling Costs
Efficient scaling isn’t about choosing a single platform or tool. It comes from combining architectural practices that work together to remove friction and waste.
Predictable environments instead of manual setup
With infrastructure as code (IaC), environments become consistent and reproducible. Systems behave the same way across testing and production, which reduces failures and support time.
Elastic capacity instead of fixed resources
Modern systems scale dynamically. Resources expand when the load increases and shrink when demand drops. This prevents paying for unused capacity while still maintaining performance.
Continuous delivery instead of large, risky releases
Frequent small releases are safer than rare large ones. Automated pipelines reduce deployment risk and allow teams to ship faster without increasing operational stress.
Visibility instead of assumptions
Observability tools show what is happening inside systems and how resources are consumed. Real data makes optimization precise instead of reactive.
Many companies try to control infrastructure costs by switching providers or negotiating pricing. In practice, pricing differences are rarely the main issue. Architecture decisions usually have a much bigger impact on both cost and stability.
The global team Alpacked works specifically at this level, designing infrastructure that aligns with business growth logic. Experience across multi-cloud platforms, Kubernetes ecosystems, automation frameworks, and monitoring systems shows a consistent pattern: companies that plan architecture early scale faster and spend less fixing problems later.
Projects that scale smoothly often share one characteristic – infrastructure decisions are treated as product decisions. Capacity planning, release strategy, monitoring, and cost control are designed together rather than handled separately.
Where to Start
Start with a clear understanding of the current infrastructure and how it is used. In many cases, resources are sufficient, but they are configured inefficiently or distributed unevenly across systems. That’s why companies often begin with an assessment covering utilization, scaling limits, reliability risks, and cost allocation by service/team. To make that assessment actionable, define ownership and tagging early using cloud cost allocation strategies so spending can be traced to specific teams and services.
A practical starting plan:
Review current infrastructure and spending
Identify bottlenecks and unused resources
Fix the most critical weak points first
Improve step by step
An experienced external perspective at this stage helps avoid costly mistakes, prioritize the right changes, and move toward scalable architecture faster while keeping systems stable and predictable.
What Efficient Scaling Looks Like in Practice
Scaling infrastructure without increasing costs requires deliberate design and operational discipline. When architecture, automation, and delivery processes are aligned, systems remain stable as demand grows and expenses stay predictable.
This approach allows companies to expand confidently, maintain performance standards, and support long-term business growth without unexpected technical or financial pressure.
A Practical Guide to Scaling Infrastructure Cost-Efficiently was last modified: June 25th, 2026 by Colleen Borator
Building a great piece of software is one thing, but making sure it actually helps the company grow is another. Many teams focus on the code and forget why they are writing it in the first place. When tech and business goals do not match, resources go to waste.
Successful companies find ways to bridge this gap by making strategy part of the daily workflow. This approach turns code into a tool for growth. It keeps the whole organization moving forward.
Bridge the Communication Gap
Teams often work in silos where developers do not understand the big picture. Finding a partner like TechQuarter helps bridge these gaps between technical execution and business strategy. This connection makes sure every sprint moves the needle for the company.
Clear goals help everyone stay on the same page during the build process. Having a shared vision makes the development cycle much smoother and more productive.
Better Stakeholder Contact
Frequent meetings and clear updates prevent issues from happening as projects move forward. Keeping these lines of contact open allows for quick pivots when business needs shift.
Teams that talk often can catch problems before they become expensive mistakes. Strong communication leads to better software that actually meets user needs.
Focus on Strategic Objectives
Software should never be built just for the sake of having new tools. A report from Theseus.fi found that communication gaps with stakeholders are a major reason projects fail. One study from unboxedtechnology.com mentioned that projects where everyone’s interests are aligned are 3 times more likely to succeed.
A paper on worldscientific.com suggested that tying software activities directly to strategic goals justifies the cost of IT. Research on emerald.com supports this idea by showing that strategic alignment helps companies outperform others. Managers should look at every feature to see if it fits the primary mission.
Modern Standards
Digital access is becoming a huge deal for employers worldwide. The reports.weforum.org site predicts that 60% of bosses expect digital access to change their business by 2030. Staying ahead of these trends requires a solid plan for future growth.
Companies must adapt to these shifting needs to remain relevant in a global market. These changes happen fast – and require constant attention from leadership teams.
Improving Processes for Efficiency
Efficiency is about more than just fast typing. A publication from researchgate.net explained that managing IT effectively requires a balance between strategy and infrastructure. Using new tech can help with this.
According to dhs.gov, using generative AI can help coders be more productive and focus on creative tasks. These tools let developers spend less time on repetitive chores and more on solving real problems.
Use CI/CD to reduce risks.
Adopt modern measurement tools.
Provide self-service options.
Information from itsecurityguru.org notes that using CI/CD helps businesses avoid risks from large updates. It makes software releases much easier to handle. This method allows teams to push small changes without breaking the whole system.
Companies that get this right find it easier to scale and serve their customers. Focusing on alignment keeps everyone moving in the right direction for long-term growth. Clear vision is the best tool for any development project. It makes the hard work worth the effort.
Tips for Aligning Software Development with Business Goals was last modified: February 22nd, 2026 by Pete Brown
Digital properties now have to serve a global audience with wide-ranging abilities, preferences and needs. Whether it’s banking applications, e-commerce websites, or enterprise SaaS tools, every user uses software differently. Accessibility is not a checkbox or post-release audit if organizations are striving to deliver a seamless user experience. It is a foundational expectation.
Assistive technologies such as screen readers, voice commands, magnifiers and switch controls are used by millions of people. Inaccessibility is not only a source of frustration for this customer base, but it can also pose reputational risk to companies, leaving them open to lost revenue and legal backlash. Nevertheless, it remains a common situation to test for accessibility late in the development cycle – typically after design and development have already been finished.
In this article, we explore what shift left exactly means as we talk about accessibility testing in software testing, why organizations should care about it, and how teams can incorporate accessibility testing from the early stages.
What is Shift Left Accessibility Testing?
Shifting left is just a fancy way of saying that you should bring your testing process into the earlier stages of the software development lifecycle. Historically, accessibility testing has been an activity pushed to the end. Some even did it just before a major release. And of course, that approach quickly exposed problems which led to design changes, component rewrites, and layout rearrangement. This caused repairs to be slow, costly, and unwelcome.
This mindset is reversed by the shift left accessibility testing. Instead of it being the sole responsibility of QA, accessibility can be shared by everyone. Product managers script diverse user stories. Designers follow accessibility principles. Developers write accessible code. QA groups perform automated and end-user-focused accessibility testing throughout development.
This early intervention lays the groundwork for accessibility to be built in. It keeps accessibility issues from filtering into the end product. It also quantifies and traces back accessibility requirements from the outset.
Why Shift Left is important in the context of Accessibility Testing
In today’s digital landscape, web and mobile applications must be usable by everyone, including the 1 in 4 adults worldwide who live with some form of disability (WHO, 2024). Accessibility is no longer an optional feature or a nice-to-have – it is a legal, ethical, and business imperative.
Regulations such as the Web Content Accessibility Guidelines (WCAG), the European Accessibility Act (EAA), the Americans with Disabilities Act (ADA), and India’s Rights of Persons with Disabilities Act, 2016, increasingly hold organizations accountable for inaccessible digital products. Failing to meet these standards can result in costly lawsuits, reputational damage, and exclusion of a significant user base.
Reduced Cost of Fixing Defects
There is little cost to resolving accessibility issues at the design stage. Developers fixing the bugs cost more. It’s so costly to fix them post-release, too, because multiple teams need to rewrite the same feature.” Shift left minimizes this cost multiplier by identifying problems earlier.
When you can do things at the right time, even something as simple as labelling form fields or redefining colour contrast is easy. But that same fix can become problematic when dozens of screens and other pieces are built on top of the original decision.
Unified Experience for All Users
Accessibility improvements benefit every user. For example, keyboard control is more efficient and supports power users. Enhanced layout functionality makes for a more accessible utility to everyone. Shift left is about building accessible experiences by default instead of adding them post-design.
Higher Compliance and Lower Risk
Such standards would include, but are not limited to the following: WCAG 2.1 or WCAG 2.2, ADA, Section 508, EN 301 549 and local accessibility laws. Late identification of concerns is a threat to compliance. Initial tests can also help maintain compliance when rules change.
Less Accessibility Debt
Analogous to technical debt in which shortcuts were taken, when teams ignore accessibility in their early stages, accessibility debt piles up. This leads to hard-to-debug, costly problems down the line. Shift left prevents long-term accumulation.
Stronger Collaboration Across Teams
Accessibility is everyone’s responsibility. Shift left promotes collaboration among designers, developers, QA engineers, and product teams. It fosters a culture of inclusion and ownership.
Shift left accessibility testing is about embedding accessibility checks early and continuously in the development cycle so issues are caught before release. LambdaTest enables this by offering tools that automate accessibility scans, integrate them into build and CI/CD workflows, and produce actionable insights early in development. This helps teams fix barriers sooner, reduce rework, and build more inclusive software from the start.
Features:
Automated accessibility scans that run as part of test suites.
Integration with automation frameworks like Selenium, Cypress, and Playwright.
Central dashboards showing accessibility issues alongside functional test results.
Customizable checks based on accessibility standards such as WCAG, ADA, and Section 508.
Tools that identify missing alt text, contrast problems, and ARIA issues in code.
Accessibility DevTools for browser-based scanning and debugging.
Semi-automated keyboard navigation checks to validate interactive flows.
Scheduled accessibility tests for continuous monitoring and regression detection.
Detailed reports with issue context to help developers fix problems early.
Embedding Accessibility for Software Testing
Shift left is only effective when accessibility is incorporated into every stage of the SDLC. Following is a blueprint for how organizations can organize their accessibility efforts across design, development, and testing.
Requirements and Planning Stage
Accessibility starts with clear requirements. Without clear criteria around accessibility, you’ll be operating on assumptions. This leads to inconsistent implementation.
Activities in this stage
Write accessibility targets for the product.
Define the level of adherence that should be achieved, often WCAG 2.1AA or WCAG 2.2AA.
Include WCAG2.0 AA as AC for all user stories.
Create personas that reflect people with disabilities.
Provide a product-wide accessibility checklist that every feature has to meet.
Educate teams about what good accessibility looks like.
Example user story
“As a screen reader user, I want to be able to work through all interactive elements in an intuitive flow” == Acceptance Criteria Video/Recording: Being able to navigate sequentially, without any jumps and tab into each modal or link without breaking order.
Design Stage
Design accessibility is one of the key drivers for shift left. Designers should make inclusive thinking part of the wireframe and visual design process because developers will inherit accessible structures fairly effortlessly.
Design considerations
Maintain adequate color contrast.
Typography that scales and is easy to read.
Don’t use color alone as the only form of communication.
Provide clear focus indicators.
Create consistent navigation patterns.
Make it easy to tap, and provide the proper spacing for touch targets.
Include alt text directions for images and icons.
Markup accessibility information right in Figma or Sketch.
Tools that support designers
Stark for color contrast checking
Figma accessibility plugins
Contrast Ratio tools
Color blindness simulators
How does this help shift left?
It all adds up, and catching those contrast issues or layout problems in design saves developers (and QA) from a lot of extra work down the road. Freehand design Documentation serves as the first pass on quality control.
Development Stage
This is where shift left really starts to earn its stripes. Accessibility is changed most directly by the developers. Their code encodes whether a screen reader can read a button properly, or a keyboard user can navigate a menu, or if low vision users can enlarge the text without causing it to break layout.
Developer best practices
Use semantic HTML whenever possible.
Use alt text to describe the images.
Don’t use divs for things that should be clickable – those are real buttons.
Use ARIA attributes carefully and only when they are necessary.
Make sure that the UI elements can be reached with the keyboard.
Add skip links and organize headings logically.
Keep the focus states and ditch removing outlines.
Use the time to build reusable accessible components, especially complex ones like modals, carousels, accordions and dropdowns.
The testing for accessibility needs to be automated and manual. Automated checks can catch the most common problems quickly, but manual testing thoroughfare check of typography with copy ensures that a product simply works for real users with disabilities.
Automation usually spots the following sorts of issues:-
Missing alt text
Low color contrast
ARIA attribute misuse
Missing labels
Empty buttons or links
Keyboard traps
Improper heading structures
Manual testing coverage
Manual evaluation includes
Keyboard-only navigation
Logical focus order
Screen reader behavior
Dynamic content announcements
Zoom and reflow testing
Gestures on mobile devices
Compatibility with assistive technology
Tools for manual testing
NVDA and JAWS for Windows
VoiceOver for macOS and iOS
TalkBack for Android
Magnifiers and zoom tools
Deployment and Pre-release Validation
The last thing before a release is that accessibility should be treated like the performance or security check and reviewed for one final time.
Activities in this stage
Comprehensive audit through all pages and flows
Cross-browser and cross-device accessibility validation
Generating accessibility conformance reports
Preparing VPAT documentation if required
Address high-severity and critical ones before release
Maintenance and Continuous Improvement
Accessibility doesn’t stop at rerelease. New access issues can emerge as UIs change and new functionality is developed.
Continuous accessibility activities
Rerun automated accessibility tests every PR.
Add accessibility tests to the CI(as code) effort
Conduct quarterly manual audits
Track user feedback, particularly from users who use assistive technologies
Train new team members
Keep an accessible design system of patterns that can be reused
Why shift left speeds up continuous improvement
Accessibility problems are being resolved early and often, rather than accumulating. Teams keep a good access posture from one release to another.
Pitfalls and How to Avoid Them
Shifting left sounds great in theory, but many teams stumble when they try to implement it. Here are the most frequent traps and practical ways to dodge them:
Lack of Accessibility Awareness
Many teams have no visibility of, or even a misunderstanding about, what accessibility really means.
Solution: Introduce internal training, workshops and documentation.
Level of Skill in Manual Accessibility Testing
And nobody wants to test a screen reader or keyboard hands-on.
Solution: (1) Regular training and (2) partnering QA with accessibility specialists.
Perceived Increase in Workload
Developers on teams might perceive accessibility as a drag on developing.
Solution: Adopt automation early and invest in reusable component libraries.
No Standardized Tools
Different teams use different tools.
Solution: Implement a common approach for the accessibility testing workflow. Incorporate tools like Axe, Lighthouse and TestMu AI.
Limited Organizational Priority
Leadership may not prioritize accessibility.
Solution: Communicate, in terms that the business will understand, why accessibility matters.
Best Shift Left accessibility testing practices to follow
Start accessibility during requirement gathering
Annotate accessibility in design files
Create reusable, accessible components
Add source code accessibility checks in tests and CI pipelines
Automated accessibility scans are your friend (early and often)
Conduct screen reader and keyboard testing on every release
Constantly focus on and improve accessibility measures
Conclusion
Accessibility can never be forced in at the last minute. By moving accessibility testing to the left of the development lifecycle, teams can find problems sooner, shrink release lags, and design products with inclusivity and compliance built in.
When companies implement the right mix of design discipline, development best practices, QA strategy, automation and real-device testing platforms like TestMu AI, they can dramatically improve their accessibility results. The payoff: better user experiences, increased compliance, less rework and products that really work for all users.
Left shift accessibility is a culture, not just a practice. It’s a mentality for creating better software from the start.
Shifting Left: Integrating Accessibility Testing in Software Testing Cycles for Early Detection was last modified: February 17th, 2026 by Rahul Jain
To have improved quality software in lesser time, the modern-day QA teams are under immense pressure, causing many organizations to rethink their test management strategy! Manual planning, inflexible documentation and static test cycles define traditional processes that were once effective but now struggle to keep pace with rapidly evolving development environments.
With the help of AI-driven insights, teams can expect risks, plan better, and have 24X7 visibility across testing activities, thus reshaping the entire landscape! With applications scaling up and delivery cycles shortening, there needs to be an evolution of test management into an intelligent, adaptive, and insight-driven discipline that strikes a balance between speed and accuracy.
AI does not replace testers. But rather strengthens decision making, reduces unnecessary work, and guarantees that planning remains consistent, if not correct, for complex projects. A new approach to test management has emerged, with the help of predictive analytics, natural language understanding, and automated reasoning that will help teams strategize and allocate their resources better.
The Evolution of Modern-Day Testing
Today’s applications have a high level of complexity that requires testing approaches that are flexible, data-driven and able to adapt to ever-changing requirements. This is different from traditional methods that fail and have static test cases, manual prioritization, and siloed information. This leads to bottlenecks and an increase in the chances of not spotting critical defects before release.
QA now needs to respond to new features, architectural changes, and user expectations at the same rapid pace at which development teams are continuously pushing updates. AI plays a major role in filling this gap by identifying patterns to predict where the device will fail and what is taking precedence attention-wise. This turns test management from a reactive task to a proactive, insight-guided activity.
Testing organizations desire something better than test case execution reports. They want strategic guidance. They want visibility into risks. They demand systems that can self-adapt. Intelligence, Automation and Collaboration: Modern test management must meet these demands.
How AI Is Changing The Way We Plan Our Tests
With AI comes abilities that ground planning in reality and are closer to more accurate data outputs. Rather than depending only on human intuition or records, AI aids in providing relevant insights by analyzing code changes, user behavior, defect patterns, and previous test failures. This leads to improved prioritisation and enables the selection of the areas of highest risk in the application for teams to focus on.
AI-driven planning improves coverage as it reveals functions that are commonly overlooked. It also helps find duplicate scenarios and save execution time that is not useful. This leads to a streamlined planning process that directly links planning with business objectives.
With software ecosystems changing at a rapid pace, AI assists test managers in keeping track of the correct development speed and its objectives. This helps make planning quicker, more adaptable and less uncertain.
Smarter Requirement Analysis with AI
An example of some of the test management problems is requirements comprehension. Requirements are vague, documented inconsistently or communicated through multiple channels. Failure to interpret results in partial coverage, repeated test cases, or key scenarios not being covered.
AI helps with requirement documents, user stories, or acceptance criteria to gain real-time and actionable insights, which can uncover hidden requirements, potential edge cases and the logical dependencies. Doing this will help to reduce ambiguity and increase the precision while planning your tests.
Disaggregate complex features in structured testable components with AI. This speeds up scenario creation and ensures every requirement is covered. It also helps teams maintain a stronger overall coverage by maintaining the traceability between the requirements and the tests.
AI-Assisted Test Case Generation
One of the most resource-intensive areas of test management is the creation of test cases. Manually generating thousands of test scenarios is time-consuming and may result in inconsistent quality, too. So here AI helps you create structured test cases based on functionality, user flows, and expected results.
By analyzing the application behavior, existing test suites, and historical defects, AI will recommend scenarios that mirror actual usage patterns. This allows for better coverage and adapted scenarios grounded in real user journeys. It lightens the load of manually drafting test cases that testers will be able to hone and verify.
The idea behind AI-driven test case generation is providing a set of test cases with a high level of confidence in accuracy, consistency, and, of course, huge scalability. In small-to-midsize applications, this practice helps you stay relevant as the application changes and grows.
Enhancing Prioritization with Predictive Analytics
At the very core of managing tests lies the concept of prioritization. They need to determine what to test first, where deeper validation is needed, and which scenarios can be deferred. Manual prioritization is frequently biased or stale.
AI employs predictive analytics to determine the most likely failure-prone features, modules that have high defect density or areas with recent code changes. This allows for data-driven risk-based prioritisation. This allows for a more targeted, efficient execution of tests that more closely align with critical business functionality.
Armed with AI-backed prioritization, test managers can plan cycles in a manner that helps them stay away from over-testing and under-testing.
AI-Powered Insights For Debugging & Defect Analysis
In a world of huge systems and complicated architecture, a lot of QA time is spent on debugging. However, AI tears down this cycle by scanning through logs, error messages, and failure patterns to recommend possible culprits.
AI identifies these systemic problems by classifying failures that occur in similar modules or by identifying issues that appear across multiple modules. This helps in expedient resolution and early intervention.
Better fault analysis additionally helps in planning the tests for the coming days. AI recognizes trends in defects and forecasts the probable locations of future defects. This feedback loop helps to ensure that the plan is based on real-world data and application behavior.
Platforms such as TestMu AI (Formerly LambdaTest) strengthen test management by unifying case design, execution, and reporting in one workspace. It helps teams create structured test plans, track progress, and understand results without switching tools. This consistency lowers coordination effort, reduces duplication, and keeps everyone aware of quality risks throughout development. The platform supports both manual and automated workflows for full lifecycle coverage.
Features:
Easy test case authoring with reusable steps and templates.
Bulk editing and organization options for large repositories.
Linking of bugs and test results for faster triage.
Import and export options for moving data from other tools.
Version control for updating and reviewing test cases.
Evidence capture during execution, including logs and screenshots.
Unified view of manual and automated test runs.
Custom fields and tags for better filtering and reporting.
Improving Collaboration Across Teams
Collaboration is necessary – between all the teams involved in test management - QA, development, product, and business teams. Yet, poor communication can be a source of misunderstandings, redundant tasks, and delayed releases.
AI alleviates this burden by summarizing documents, translating complex content into layman’s terms and creating a standardized document. It renders communication decisive and uniform. Provide transparency – Teams can leverage AI to create test reports, user flow summaries, and release notes for better transparency.
Seamless information sharing: intelligent collaboration tools rely on analytics to ensure that cross-functional teams can share information within the organization seamlessly, accurately, and without silos. This minimizes the bottleneck and enables the process of ongoing improvement.
Coverage Over Device And Platform Variation
In the era of multi-device and cross-platform applications, coverage has emerged as the most complicated dimension of test management. Having applications that work everywhere across mobile devices, browsers, operating systems and screen sizes comes with a lot of infrastructure and planning.
But physical device labs are an impossibility for many, and cloud-based execution environments help address this challenge by having access to real devices and browser combinations without requiring them. You can scale up more easily, and teams can test across a wide variety of environments without having to manage servers.
AI takes this up a notch by detecting device-specific risks, flagging configurations with higher failure probabilities, and recommending device-focused test strategies. This ensures that coverage is both complete and reflects what customers actually experience.
So, how does TestMu AI help you with Smart Test Management
In this shift towards intelligent test management, the test execution environment is a major contributing factor to test accuracy and reliability. With real device and browser execution on scale, TestMu AI fortifies test management workflows. It allows teams to verify that the planning driven by AI actually is manifested in the real world.
TestMu AI enables teams to run manual and automated tests across hundreds of environments. This eliminates the hassle of managing physical devices and maintaining consistency in execution. Teams can discern issues quickly and align debugging with AI insights as detailed logs, network information, screenshots, and video recordings are available.
TestMu AI has also been quite in sync with the modern test manager’s needs. The best part is its capability to blend within pipelines, parallelize execution, and provide consistent results across environments – all of which support better strategic planning and execution. TestMu AI also provides a lot of execution data, which can be fed into AI analytics, thus making the ROI calculation on AIOps far richer and targeted for teams working with AI-driven analytics.
But on the good side, because TestMu AI is a part of a cloud-based testing ecosystem, it improves coverage and provides a way to follow continuous quality efforts. This enables teams to create repeatable, insight-driven workflows that drive test stability and resources and shorten time to releases.
The never-ending cycle of improvement with AI-based data insights
Continuous evaluation and improvement are necessary for good testing management. AI plays a big role in this by analyzing historical data, examining coverage trends, monitoring defect trends, and pinpointing improvement areas. These insights ensure that strategies are in line with changing application behavior.
By leveraging AI, teams will be able to identify testing gaps, optimize test suites, eliminate redundant scenarios and bolster high-impact areas. It creates a culture of continuous improvement where test management turns from proactive to reactive.
Together, AI Insights, along with Scalable execution platforms, have the potential to help organizations develop resilient and future-ready testing ecosystems.
The Future of Test Management
Intelligence, automation, and adaptability to change are the future of test management. AI will further enhance team planning, prioritization and execution of test activities. This technology will enable predictive analysis, natural test generation, and risk-based decision making.
Test managers will move from dealing with human resources to strategic direction and measurement, aided by tools that highlight information and take over routine tasks. By enabling this change, teams can spend more time on the creative, the analytical, and on being advocates for quality.
As organizations embrace AI-driven test management, they will see enhanced productivity, enhanced coverage, and predictable releases.
Final Thoughts
With the introduction of AI-powered capabilities like intelligent planning, immediate debugging and smart decision making, test management is quickly transitioning. QA requires solutions that help not only to facilitate test execution but also to reinforce its strategic foundation. This objective is done through AI-driven insights that not just interpret data but also identify risks while adjusting coverage across the evolving application landscape.
However, the planning is only as effective as execution: With platforms such as TestMu AI facilitating scalable execution in real environments, teams can now mitigate the risk of an ineffective plan leading to unreliable results. TestMu AI gives test managers the confidence to deliver high-quality releases on time with the infrastructure, consistency, and visibility that modern test management requires.
The era of intelligent and scalable test management has arrived. In short, with the right practices of AI-focused technologies paired with cloud-based execution environments, organizations can manifest a stronger, competent and future-ready QA process.
Test Management Evolved: Smarter Planning with AI Insights was last modified: February 17th, 2026 by Rahul Jain
Generative AI transforming software testing is advancing faster than even analysts anticipated just 12 months ago. By 2025, the best engineering teams will no longer spend weeks writing and maintaining brittle UI scripts or testing critical paths if it slows development down due to resource limitations. Instead, they employ the next generation of AI-first tools that not only create and heal but also optimize tests that can even run on their own with little human intervention.
TestMu AI (Formerly LambdaTest) KaneAI is a generative AI test agent that helps teams plan, create, run, and evolve end-to-end tests using natural language. Users describe what they need tested, and KaneAI turns that intent into structured tests that cover UI, API, database, and accessibility layers. It reduces the learning barrier for automation and scales testing across environments and devices.
Features:
Create automated tests from plain language descriptions.
Generate full test scenarios from text, documents, and tickets.
Unified validation of UI, API, databases, and accessibility.
Smart visual comparison for pixel-level differences.
Automatic handling of popups and dynamic behavior.
Reusable test modules that adapt across projects.
Custom environment selection for targeted test runs.
Native integration with issue tracking and workflow tools.
Flexible scheduling and execution across devices and browsers.
Detailed reporting and analysis of test outcomes.
Cursor + Playwright/TestRunner
If you’re a developer using Cursor (the AI-first IDE based on VS Code) with methods from the Playwright or Jest framework, you can write complete end-to-end and component test suites 8–12× faster than coding them out by hand. Cursor’s Integrated Composer mode learns about your component lib, design system tokens, and current testing patterns – and then writes in-SSR-type-safe, humans-readable Playwright tests in seconds.
Real-world workflow in 2025:
Highlight a user story → “Create E2E flow with happy path + 6 edge cases”
Cursor automatically generates page objects, test data factories and visual regression checks.
Click-to-“explain” flakiness when CI fails
Results: Developers at companies like Vercel, Replicate, and Ramp are 75 %+ AI-contribution today as a part of their Playwright suite, which is maintained by the very same tooling.
Keploy (Open Source + Enterprise)
Keploy became a curiosity of a side project to one of the fastest adopted AI test automation tools in 2025. It captures actual production traffic (or staging) and immediately replays it as deterministic tests with mocks - no setup, teardown, or coding required.
2025 breakthroughs:
Generative mock augmentation: Generates data samples that fill real gaps in recorded flows with plausible variations
Automatic Test Generation Generator tooling for GraphQL and gRPC
Built-in data anonymization + Chaos Experiments
Native Kubernetes sidecar mode for testing service-mesh
Open-source core is still free; the enterprise offering includes security scanning and test impact analysis. Frameworks consumed at Zomato, Flipkart, & more than a few fintech unicorns.
Codium for Teams AI (Now with Integration & E2E)
Previously recognized as a unit-test creation but now offering full-stack coverage, CodiumAI 2025 was considered. The new Explore agent has the ability to crawl a running app (locally or in dev env), map the user journeys and generate Playwright / Cypress / Cypress-Cloud tests that contain accessibility & security assertions.
Standout features:
Behavioural test generation from plain tickets or Notion docs
Automatic root cause analysis-based test healing (not just DOM patching)
Heatmap “Coverage Gaps” directly within the GitHub PRs
Out of the box support for React, Vue, Angular, Svelte and SolidJS
Average time between new features into 90 %+ automated coverage: under 4 hours.
Well adopted in European fintech and govtech, where, due to regulatory scenarios, coverage is obligatory.
Ponicode (now part of CircleCI)
Purchased by CircleCI and re-released in 2025 as generative in whole. Ponicode lives in every PR: it reads the diff, anticipates potential points of failure and creates targeted regression tests before merge.
Key metrics from CircleCI customers:
40% decrease in production escape bugs
-more than 65% of newly introduced unit and integration tests are synthetically generated by AI
Supports JavaScript, TypeScript, Python, Go and Rust
Gremlins. AI Fuzzing Extensions (Unleashed) for JS
The traditional chaos-monkey library also received a generative AI-on-the-side community extension. The “Gremlins Forge, on the other hand, utilises LLMs to generate semantically valid attack instances rather than random clicks.
For example, it doesn’t just click buttons at random; rather, it knows about login flows and shopping carts and payment forms – then “intentionally” dismantles them in lifelike ways. Teams use it as their last-minute sanity check before they push to production.
Internal RAG GenAI Agents (The Dark Horse Winner)
The most exciting thing in 2025 is not any commercial tool, but that enterprises are building private testing agents using Llama-3. ) variants of Mistral fine-tuned on each team’s own component library, design tokens, and historic bug data.
Typical stack:
LangGraph + Playwright
Previous test failures vector database
Slack/Teams bot that elicits QA by typing “test the new checkout flow with coupon stacking”
Shopify, Atlassian, and many FAANG teams all openly acknowledge that their internal agents now account for 60–80 % of all new tests.
Gremlins. js + AI Fuzzing Extensions (Unleashed)
An AI extended version of the classic chaos-monkey library, keeping up with the spirit of community extensions. Instead of a random click, “Gremlins Forge” uses the new LLMs to form semantically meaningful attack sequences.
Example: It doesn’t mindlessly click buttons, it understands login flows, shopping carts and payment forms—and then smashes them to pieces in lifelike ways. Teams use it as the last sanity check prior to production pushes.
ACCELQ (Enterprise Natural Language Automation)
ACCELQ is unique with its natural language modeling for business users, the industry’s only cloud-based, AI-integrated codeless test automation. The 2025 version brought with it:.Logic Pro: The new Logic Insights AI co-pilot analyzes test designs and makes optimization recommendations based on historical data.
Why it’s revolutionary:
Intake requirements from Jira/ Confluence or even Figma to auto-generate test repo.
Predictive analytics for high-value areas with risk-based test prioritization
API, WEB, MOBILE & ERP (SAP/ORACLE) Coverage integrated in one solution
ACCELQ Universe to visualize and share tests in Real-time
Fortune 500 customers are achieving 70% cuts to test creation time and improved compliance via audit-ready traces. It’s especially strong for regulated businesses, such as those in the financial or health care industries.
Katalon Studio (All-in-One AI Scripting)
Katalon Studio became a GenAI marvel in 2025, integrating low-code scripting with AI-assisted capabilities for full-stack test lifecycle management. It has since adopted GPT-like models to generate tests from user stories or code diffs, which makes it a go-to for hybrid dev-QA teams.
Key innovations:
Smart XPath, and self-healing for resilient UI interactions
using AI to detect and automatically fix flaky tests
Built-in record and playback for visual testing integration
Combines everything: desktop, mobile, web and API
Available through free community editions and scalable enterprise licensing, Katalon has experienced explosive growth in the SMB space, providing over 50% improvement in test coverage without steep learning curves.
TestGPT by DeepScenario
DeepScenario, which was first developed for autonomous driving scenario generation, repositioned TestGPT for the purpose of general software testing in 2024. It is good at creating complex multistep scenarios from fuzzy requirements.
Why it stands out:
Multimodal input: accepts text, wireframes, Loom videos or Miro boards.
Results in a combinatorial explosion of valid edge cases
Generates tests in Gherkin, Playwright or Robot Framework files
Most powerful test generation for accessibility available today
Used a lot in European fintech and govtech, where regulations require full scenario coverage.
Reflexion Testing (Research → Production)
Born from academic papers on the topic of “agentic testing,” Reflexion is today a production-grade open-source framework with commercial hosting. The AI agent runs experiments over and over, watches for failure, thinks things out, tries again and tweaks the tests until they are always passing.
2025 reality:
Reaches 99 %+ stability even on very dynamic SPAs
Improves and automates both test data and assertions, unassisted by humans
Can be used with all test runners (Jest, Playwright, pytest, etc.)
Early adopters are a set of AI-native companies that deploy 50+ times per day.
Workik AI Test Generation
A nice under-the-radar (pre-2020) riser in 2025. Workik brings RAG to the whole of your repo + design system + Figma files, to drive pixel-perfect, data-driven tests.
Unique strengths:
Translates Figma components into test steps on the go
Provides realistic test data following your Prisma/PostgreSQL schemas
Single-click turn around of manual QA sessions (by screen capturing) into script tests
Compatible with Playwright, Cypress and WebdriverIO
It’s a favorite among startups and mid-size SaaS companies because it doesn’t take any new infrastructure.
The 2025 Testing Paradigm Shift
The old world (teams of talented engineers manually hand-coding their XPath locators, spending 40 % of every sprint on maintenance, while seeing 15–30 % of priority bugs escape into production) is crumbling faster than anyone imagined.
Generative AI has transitioned from a test pilot to the lead author, healer and executor of most of the tests in the industry. What started as “AI-assisted testing” in 2023–2024 has evolved into quality engineering on autopilot: Tools that ingest requirements, Figma files, production traffic or just a simple sentence in plain English and produce resilient, data-driven self-healing test suites within minutes instead of weeks.
The outcome is not “incremental” efficiency; it’s a total reinvention of velocity, coverage, and risk. The organizations that’ve embraced this transition are shipping 3–10× more frequently with a commensurate increase in confidence, while the ones that are still scripting their tests line by line find themselves at a competitive disadvantage measured not just in percentage points but also in time. No longer a trend, this is the new normal.
Unit → complete autonomous (Diffblue, CodiumAI, Ponicode)
Integration/API → traffic-to-test time (Keploy) Types of Ads served to provide a seamless experience: Video, Display and Rich Media.
E2E/UI → natural language or recording → production-grade suite (Cursor, Workik, TestGPT)
Exloratory & chaos → AI that never sleeps
Conclusion
If you are still searching for that exact right string of XPath, debating the best wait strategy, huffing and puffing as half your suite lights up red over a minor CSS change, then you’re playing this game the way we did three years ago. That era is over. The teams that win today (the ones that are shipping multiple times per day and have a sub 1 % production defect rate) think nothing of completely changing when testing happens. So here’s the actual playbook they use, as we’ve seen it play out:
Install one IDE-native generation tool (Cursor, CodiumAI or GitHub Copilot X + Playwright mode) for developers.
Over there, from 70 to 90 % of all new tests are created. As soon as the feature branch is made, the AI knows your component library, design tokens, accessibility rules and your past bugs. Developers no longer “write tests” as they previously understood the phrase; now, they review, tweak and commit AI-generated test suites in seconds.
Real numbers from 2025:
Time from pull request open to 85 %+ automated coverage: <7 mins.
Developer happiness with testing: 89 % of developers who answered the State of Testing Report 2025 have been compared to around only ~42 % in 2023.
This bypasses the age-old “but did we test the actual user flows?” debate. The production/staging traffic is recorded once (anonymised) and immediately transformed into deterministic mocks & tests. No more speculating which combinations users actually hit – Keploy (and friends) create the precise payloads, headers, rate limiting conditions, and chaos scenarios that people do in practice.
The outcome: regression suites that more accurately resemble reality rather than a figment of someone’s imagination.
Let the AI do 70–90% of creation and 95%+ of maintenance
Self-healing is now table stakes. Modern agents not only patch the broken locator, they infer why the element moved (Tailwind was upgraded? New component version? Dark-mode toggle?) and semantically edit the whole step. Flaky test investigations, which used to take hours, are now whacking through in <30 seconds with a simple line of expl and AF PR.
The effort to maintain it has been reduced so much in some organizations that companies have completely broken cross-functional test-automation teams and distributed them directly into feature teams.
Leave it to the humans for strategy, strategic risk analysis, and the toughest 10 %”.
It is the primary shift of mind. Humans are no longer the script monkeys but the risk managers. Their time is spent on:
Determining what deserves exploratory testing/chaos experiments
Specifying compliance and regulatory failure/edge cases where human expertise is needed (e.g., ethical edge cases in AI products)
Addressing faulty AI coverage gaps identified using behavioral analytics
Creating “what-if” scenarios that have never occurred in production… but
Everything else, happy paths, negative cases, data hydration and composition, cross-browser matrix explosions, accessibility checks, and performance regression detection is entirely automated.
The generative AI testing revolution is not on its way – it’s here, and it’s already open source (or sold for a pittance) and can work on codebases spanning any size from two-person startups to 50-million-line monoliths. Other than that, the only real question in 2025 is how long your company wants to pay the increasingly higher competitive tax of testing the 2018 way. The distance is no longer measured in weeks of lost productivity – it’s measured in market relevance.
Top Generative AI Tools Revolutionizing Software Testing was last modified: February 17th, 2026 by Rahul Jain